ЗНАЧЕНИЕ МИРОВОЗЗРЕНИЯ
Дерзайте ныне ободрены
Раченьем вашим показать,
Что может собственных Платонов
И быстрых разумом Невтонов
Российская земля рождать.
«Ода на день восшествия на престол Елисаветы Петровны 1747года». Ломоносов М. В.
Каково мировоззрение человека, таков и путь он для себя выбирает. Мировоззрение начинает формироваться с детства, и, конечно же, большое значение в этом имеет школа. Если в современных школах преподают по все более упрощенным программам и значительное время отводят «сексуальному воспитанию», вернее, концентрируют внимание школьников на половых отношениях, сексуальных удовольствиях, заявляя, что и дети имеют на это право, то в центре мировоззрения, таким образом воспитанного человека, будет примитивный труд и секс.
Существует спектр интересов от самой низкой его части, о которой мы только что говорили, и до самой высокой, которая соответствует высоким стремлениям, истинному героизму, духовности. Какую часть спектра интересов занимает человек, зависит от его мировоззрения. Мировоззрение – это система взглядов на жизнь природу, общество. Для одних людей формирование мировоззрения заканчивается, когда они приобретают определенную профессию и умение вести свое домашнее хозяйство. Но есть еще более примитивное мировоззрение, которое не включает в себя семьи, а только работу и удовольствия, да и то, работа при таком мировоззрении занимает место досадной необходимости.
Мировоззрение содержит в себе три основных аспекта: первый из них – это знания. Второй – отношение человека к реальности этого мира, третий – смысл всего сущего и смысл своего собственного существования. Отдельно стоят личностные особенности человека, которые в значительной степени зависят от наследственности и условий существования человека.
Сами по себе знания, которые получает человек, или информация, которой он заполняет свою память, ещё не делает его ни высоко культурным, ни духовным. Всем этим содержимым образованного человека можно заполнить компьютер и от этого он не станет ни лучше, ни хуже; можно прочитать много умных книг и, тем не менее, остаться глупым.
Очень важным является отношение человека к окружающему миру, в котором он может быть потребителем и тогда это наихудший вариант, и он может осознавать себя частью этого мира и свою ответственность перед ним. В отношение человека к окружающей его реальности так же входит знание предназначения всего сущего в мире.
И, наконец, отношение человека к самому себе и своему предназначению в этом мире. Он должен знать, что мир, в котором он родился, является для него школой, в которой он может приобретать не только внешний опыт, помогающий ему выжить, но, самое главное, – он должен знать, что реальность этого мира служит для него трамплином, оттолкнувшись от которого он может встать на путь, ведущий к его предназначению.
В чем состоит значение мировоззрения для деятельности человека?
Изменить мир в одиночку, человек способен только внутри себя, он сам — мир до сих пор неизвестных возможностей, и каждый индивидуален по-своему. Тут никакие поговорки и отговорки не подходят, и о войне нет речи. Действительно, любое изменение нужно начинать с себя, независимо о каком мире упоминается. Но далее, изменяя себя и добившись определённых успехов в самосовершенствовании, один человек не сможет повлиять на остальных, если они остаются стоять на месте, ибо это не его власть и даже не Бога, каждый человек имеет право выбирать и решать что ему менять в себе и как, иначе мы жили бы в обществе марионеток подчинённых одной воле. Кстати, навязанные правила успеха гражданского общества медленно но верно ведут сознание к общему знаменателю, что похоже на марионеточную политику… О любви, добре, счастье, чести, совести понятия искажены а истинные устарели. Деньги, машины, кредиты, карьера, бизнес, политика, зрелищность нынче на слуху как 2х2, и цена человеческой жизни уже принята за некий денежный эквивалент, хотя никто никому такого права не давал и дать не может. Дисбаланс уровня жизни в природе, приобрёл катастрофические масштабы, одни особи вымирают, другие страдают от перенаселённости, и в обществе людей одни жируют и делят мир, другие выживают кое-как в нищих государствах, да в самих государствах законы и коррупция не способствуют равномерному развитию. Всё это ведёт к медленному, но верному глобальному самоуничтожению. Пора бы с этим прекращать, мягко говоря, а нет, видимо, ещё не наелись или ума не хватает осознать, что ущербность конечна и любая утопия приведёт в тупик рано или поздно. Как тут изменить мир? Кто понимает, тот начинает с себя, своим поведением, своими действиями. А кто пляшет под дудку «благосостояния», те являются индикатором всеобщего развития интеллекта, и они пока элементарно не знают, или не хотят знать о своих возможностях, для них жизнь заканчивается со смертью их тела, и им плевать что будет после них. До поры, до времени…
Духовный мир личности. Духовно-нравственные ориентиры человека
- ГДЗ
- 1 Класс
- Окружающий мир
- 2 Класс
- Математика
- Английский язык
- Русский язык
- Немецкий язык
- Литература
- Окружающий мир
- 3 Класс
- Математика
- Английский язык
- Русский язык
- Немецкий язык
- Окружающий мир
- 4 Класс
- Математика
- Английский язык
- Русский язык
- Немецкий язык
- Окружающий мир
- 5 Класс
- Математика
- Английский язык
- Русский язык
- Немецкий язык
- Биология
- История
- География
- Литература
- Обществознание
- Человек и мир
- Технология
- Естествознание
- 6 Класс
- Математика
- Английский язык
- Русский язык
- Немецкий язык
- Биология
- История
- География
- Литература
- Обществознание
- Технология
- 7 Класс
- Английский язык
- Русский язык
- Алгебра
- Геометрия
МИРОВОЗЗРЕНИЕ И ДЕЯТЕЛЬНОСТЬ ЧЕЛОВЕКА, МЕНТАЛИТЕТ ЧЕЛОВЕКА
Какую роль играет мировоззрение в деятельности людей? ты в процессе своей деятельности. Одна из важнейших проблем — принять мир таким, какой онє.
Во-вторых, само мировоззрение через свою философскую»сердцевину»дает людям понимание того, как достичь намеченных ориентиров и целей, вооружает людей методами познания и деятельности. Уподобляя метод фонаря, щ освещающий дорогу путнику, великий философ прошлого. Р. Декарт говорил, что хромой с фонарем быстрее достигнет цели, чем всадник, блуждающий в темнотеві.
В-третьих, на основании мировоззренческих ценностных ориентаций человека, своей деятельности она получает возможность находить истинные ценности жизни и культуры, отличать действительно важное для деятельности человека с достижением ею своих целей от того, что реального значения не имеет, носит ложный или иллюзорный характер. Именно в мировоззрении содержится понимание человеком мира и тенденций его развития, возможностей л. Иудины и содержания ее деятельности, добра и зла, красоты и безобразияа.
МЕНТАЛИТЕТ ЧЕЛОВЕКА
Рассказ о духовном мире была бы неполной без рассмотрения проблемы менталитета
Что такое менталитет человека? монастрий»,»душевность»Правы те специалисты, которые говорят, что точного, однозначного перевода этого термина пока нет. Но сам он употребляется довольно широко. Так, например, говорят о менталит ет конкретного человека. Что здесь имеется в виду? к сложная система понятий, в которых отражается многообразие окружающего человека мира и осознание ею своего места в этом мире. Менталитет — это совокупность всех итогов познания, оценка их на основе предшествующей культуры и практической деятельности, национального сознания, личного жизненного опыта. Иными словами, это увязывание различных мнений и ценностей в сознании индивида, своеобразный итоговое й сплав, что и определяет духовный мир человека в целом, ее подход к тем или иным конкретным практическим спраних справ.
Считается, что через индивидуальный процесс формирования духовного мира человека и неповторимости человеческой личности менталитет — явление в основном личностное хотя говорят и о менталитете того или иного ого социального слоя, например, о менталитете ученого, военного, бизнесмена, юриста. У всех представителей данного социального или профессионального слоя благодаря их практической деятельности, социал льное статуса (положения, занимаемого в обществе), некоторой общности жизненного пути, деятельности, которой они занимаются, есть немало общего в складе ума, в умонастроении, другими словами — в их мента литетті.
Говорят о менталитете тех или иных народов: так, в литературе широко употребляется термин»украинская душа», при этом подразумевается целый ряд психических качеств: открытость в общении, доверчивые ость, терпение, тенденция к совместной трудовой деятельности (артель, община и т.д.). Разумеется, далеко не каждый представитель украинского народа имеет эти качества, но сложилось мнение, что названные черты типично и именно для украинского народа. Современная наука о национальных общности людей — этнология пытается найти психологические черты, черты менталитета различных наций, народностей, других этнических игрууп.
Основные понятия
Мировоззрение. Убеждение. Менталитет
Сроки
Миропонимание. Мировоззрение. Геоцентризм природоцентризм. Антропоцентризм. Типы мировоззрений. Вера
Вопросы для самопроверки
1. В чем заключается сущность мировоззрения?
2. Какие типы мировоззрения выделяет наука?
3. Что такое убеждение?
4. Что общего в понятиях»мораль»и»мировоззрение»?
5. В чем состоит значение мировоззрения для деятельности человека?
6. Как влияет духовно-теоретическая и духовно-практическая деятельность на формирование мировоззрения?
7. Что такое менталитет?
8. Почему мировоззрение является формой духовно-практического освоения мира и самовыражения человека в нем?
9. Отчего философия является теоретической формой мировоззрения?
Задача
1. По мнению. О. Швейцера, мировоззрение должно соответствовать трем требованиям: быть сознательным («мыслящим»), этическим, идеалом которого является преобразование действительности на моральных принципах, оптимистичным
Какой, на ваш взгляд, развернутый содержание каждого из этих требований?
2. Проанализируйте два сделаны в разное время высказывания выдающегося русского философа. МО. Бердяева (1874-1948)
Конец XIX века:»Весь мировой путь бытия является сложным взаимодействием различных степеней мировой иерархии индивидуальностей, творчества, врастание одной иерархии в другую, личности в нацию, нации в человечество, л человечества в космос, космоса в. Бога»Конец 30-х гг XX века:»Нация, государство, семья, внешняя церковность, общественность, социальный коллектив, космос — все представляется мне вторичным, второстепенным, даже пр имарним и злым по сравнению с неповторимой индивидуальной судьбой человеческой личности»Как вы думаете, почему произошли изменения во взглядах философа?. В каком направлении менялись его взгляды?. К какому из типе в мировоззрения относится первое высказывание? ення?
3. Проанализируйте следующее высказывание видного немецкого социал-демократа. К. Каутского (1854-1938):
«Задача науки состоит вовсе не в том, чтобы дать простое изображение того, что есть, верную фотографию действительности так, чтобы каждый нормально организованный наблюдатель мог получить ту же картину. Задача на аукы, наоборот, заключается в том, чтобы в бесконечном множестве лиц, явлений отыскать общее, существенное и дать, таким образом, нить. Ариадны, с помощью которой можно было бы ориентироваться в лабиринте действительности».
Как вы думаете, касается это выражение мировоззрения?
Краткие выводы к разделу
1. Духовный (внутренний) мир личности сводит воедино ум, чувства, волю человека, характеризует личность с позиций ее отношение к окружающей действительности, к другим людям, к себе
2 духовные деятельность в различных ее видах и формах создает и развивает культуру личности и общества
3. Осваивая культуру, люди овладевают духовными богатствами народа своей страны и мира
Благодаря пониманию и признанию общезначимых национальных ценностей, свободному выбору гуманистических моральных и мировоззренческих установок деятельность человека становится активной, направленной на благо личности и и общества. Практическая реализация этих установок зависит от человеческих усилий, направленных на их осуществлениея.
Вопрос раздела
1. Сопоставьте духовно-теоретическую и духовно-практическую деятельность, покажите общую отличие, раскройте взаимосвязь этой деятельности с освоением культуры, с мировоззрением человека и его моральной точки зрения ами.
2. Охарактеризуйте главные нравственные категории. Покажите, в чем заключается взаимосвязь идеалов, ценностей, моральных норм (приведите примеры)
3. Философы утверждают: моральный выбор — это тот пункт, где абстрактные требования этики и моральная оценка реальной ситуации отражаются в принятом решении, а потом проявляются в поступке. Согласны ли вы с т такой точкой зрения? тя.
4. Раскройте сущность моральной оценки деятельности. Можно труд считать моральной ценностью? в в эти периоды наиболее опасные проявления ненависти, нечестности и ценные доброта, дружелюбие, честность, совестливость, милосердиея?
5. Охарактеризуйте сущность и типологию мировоззрения. Как мировоззрение влияет
6. Как смысл вкладывает наука в понятие»менталитет»?
7. Сформулируйте общую характеристику духовного мира личности, раскройте его влияние на деятельность человека и общества (приведите примеры)
Распознавание человеческой деятельности с OpenCV и глубоким обучением
Щелкните здесь, чтобы загрузить исходный код этого сообщения
Из этого руководства вы узнаете, как выполнять распознавание человеческой активности с помощью OpenCV и глубокого обучения.
Наша модель распознавания человеческой деятельности может распознавать более 400 действий с точностью 78,4-94,5% (в зависимости от задачи).
Образец мероприятий можно увидеть ниже:
- стрельба из лука
- армрестлинг
- печенье для выпечки
- считать деньги
- ведущий трактор
- ест хот-дог
- летающий змей
- делать тату
- Груминг лошадь
- обниматься
- фигурное катание
- жонглирование огнем
- целоваться
- смеется
- мотоспорт
- привязка новостей
- открытие присутствует
- играет на гитаре
- играть в теннис
- робот танцует
- парусный спорт
- подводное плавание с аквалангом
- сноуборд
- дегустация пива
- стрижка бороды
- с помощью компьютера
- мытье посуды
- сварка
- йога
- … и многое другое!
К практическим приложениям распознавания человеческой деятельности относятся:
- Автоматическая классификация / категоризация набора данных видео на диске.
- Обучение и контроль нового сотрудника для правильного выполнения задачи (например, правильные шаги и процедуры при приготовлении пиццы, включая раскатывание теста, нагревание печи, нанесение соуса, сыра, начинки и т. Д.).
- Проверка того, что работник общественного питания вымыл руки после посещения туалета или работы с продуктами питания, которые могут вызвать перекрестное заражение (например, курица и сальмонелла).
- Наблюдать за посетителями бара / ресторана и следить за тем, чтобы они не переедали.
Чтобы узнать, как выполнять распознавание человеческой активности с помощью OpenCV и глубокого обучения, просто продолжайте читать!
Распознавание человеческой деятельности с помощью OpenCV и глубокого обучения
В первой части этого руководства мы обсудим набор данных Kinetics, набор данных, используемый для обучения нашей модели распознавания человеческой активности.
Оттуда мы обсудим, как мы можем расширить ResNet, которая обычно использует 2D-ядра, чтобы вместо этого использовать 3D-ядра, позволяя нам включить пространственно-временной компонент, используемый для распознавания активности.
Затем мы реализуем две версии распознавания человеческой активности с использованием библиотеки OpenCV и языка программирования Python.
Наконец, мы завершим руководство, рассмотрев результаты применения распознавания человеческой активности к нескольким примерам видео.
Набор данных кинетики
 Рисунок 1: Предварительно обученная модель глубокого обучения распознавания человеческой активности, используемая в сегодняшнем учебнике, была обучена на наборе данных Kinetics 400.
Рисунок 1: Предварительно обученная модель глубокого обучения распознавания человеческой активности, используемая в сегодняшнем учебнике, была обучена на наборе данных Kinetics 400.
Набор данных, на котором была обучена наша модель распознавания человеческой активности, — это набор данных Kinetics 400.
Этот набор данных состоит из:
- 400 классов распознавания человеческой деятельности
- Не менее 400 видеоклипов на класс (скачиваются через YouTube)
- Всего 300 000 видео
Вы можете просмотреть полный список классов, которые модель может распознать здесь.
Чтобы узнать больше о наборе данных, в том числе о том, как он был подготовлен, обязательно обратитесь к статье Кей и др. За 2017 год: The Kinetics Human Action Video Dataset .
3D ResNet для распознавания человеческой деятельности
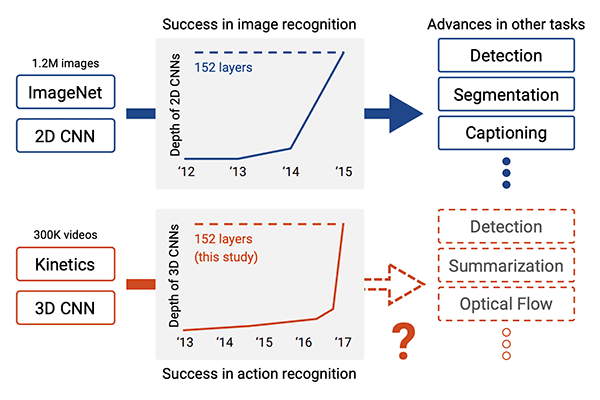 Рисунок 2: Достижения глубокой нейронной сети в области классификации изображений с помощью ImageNet также привели к успеху в распознавании активности глубокого обучения (т.е. на видео). В этом руководстве мы выполняем распознавание активности глубокого обучения с помощью OpenCV. (Источник изображения: рис. 1 от Hara et al.)
Рисунок 2: Достижения глубокой нейронной сети в области классификации изображений с помощью ImageNet также привели к успеху в распознавании активности глубокого обучения (т.е. на видео). В этом руководстве мы выполняем распознавание активности глубокого обучения с помощью OpenCV. (Источник изображения: рис. 1 от Hara et al.)
Модель, которую мы используем для распознавания человеческой деятельности, взята из статьи Hara et al. 2018 CVPR, Могут ли пространственно-временные 3D CNN повторить историю 2D CNN и ImageNet?
В этой работе авторы исследуют, как существующие современные 2D-архитектуры (такие как ResNet, ResNeXt, DenseNet и т. Д.) Могут быть расширены до классификации видео с помощью 3D-ядер.
Авторы утверждают:
- Эти архитектуры были успешно применены для классификации изображений.
- Крупномасштабный набор данных ImageNet позволил обучить такие модели с такой высокой точностью.
- Набор данных кинетики также достаточно велик.
… и, следовательно, эти архитектуры должны иметь возможность выполнять классификацию видео путем (1) изменения формы входного объема для включения пространственно-временной информации и (2) использования трехмерных ядер внутри архитектуры.
Фактически авторы были правы!
Изменив как форму входного объема, так и форму ядра, авторы получили:
- Точность 78,4% на испытательном наборе Kinetics
- Точность 94,5% на испытательном наборе UCF-101
- Погрешность 70,2% на испытательном наборе HMDB-51
Эти результаты аналогичны точности ранга 1, о которой сообщается на современных моделях, обученных в ImageNet, , тем самым демонстрируя, что эти архитектуры моделей могут быть использованы для классификации видео просто путем включения пространственно-временной информации и замены двухмерных ядер. для 3D.
Для получения дополнительной информации о нашей модифицированной архитектуре ResNet, схеме экспериментов и окончательной точности обязательно обратитесь к статье.
Загрузка модели распознавания человеческой деятельности для OpenCV
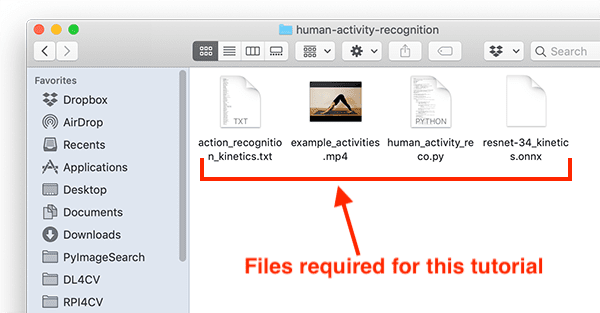 Рисунок 3: Файлы, необходимые для распознавания человеческой активности с помощью OpenCV и глубокого обучения.
Рисунок 3: Файлы, необходимые для распознавания человеческой активности с помощью OpenCV и глубокого обучения.
Чтобы продолжить работу с оставшейся частью этого руководства, вам необходимо загрузить:
- Модель деятельности человека
- Python + исходный код OpenCV
- Пример видео для классификации
Вы можете использовать раздел «Загрузки» этого руководства, чтобы загрузить файл.zip, содержащий все три файла.
После загрузки перейдите к оставшейся части этого руководства.
Структура проекта
Давайте проверим наши файлы проекта:
$ дерево . ├── action_recognition_kinetics.txt ├── resnet-34_kinetics.onnx ├── example_activities.mp4 ├── human_activity_reco.py └── human_activity_reco_deque.py 0 каталогов, 5 файлов
Наш проект состоит из трех вспомогательных файлов:
-
action_recognition_kinetics.txt: метки классов для набора данных Kinetics. -
resnet-34_kinetics.onx: предварительно обученная и сериализованная сверточная нейронная сеть Hara et al. Для распознавания человеческой активности, обученная на наборе данных Kinetics. -
example_activities.mp4: Подборка видеороликов для тестирования распознавания человеческой активности.
Мы рассмотрим два сценария Python, каждый из которых принимает в качестве входных данных три указанных выше файла:
-
human_activity_reco.py: Наш скрипт распознавания человеческой активности, который выбирает N кадров за раз, чтобы сделать прогноз классификации активности. -
human_activity_reco_deque.py: аналогичный сценарий распознавания человеческой активности, который реализует очередь скользящего среднего . Этот сценарий выполняется медленнее; однако я предоставляю реализацию, чтобы вы могли учиться на ней и экспериментировать с ней.
Реализация распознавания человеческой деятельности с OpenCV
Давайте продолжим и реализуем распознавание человеческой активности с помощью OpenCV.Наша реализация основана на официальном примере OpenCV; однако я внес дополнительные изменения (как в этом, так и в следующем примере) вместе с дополнительными комментариями / подробными объяснениями того, что делает код.
Откройте файл human_activity_reco.py в структуре вашего проекта и вставьте следующий код:
# импортируем необходимые пакеты
импортировать numpy как np
import argparse
импорт imutils
import sys
импорт cv2
# создать парсер аргументов и проанализировать аргументы
ap = argparse.ArgumentParser ()
ap.add_argument ("- m", "--model", required = True,
help = "путь к обученной модели распознавания человеческой активности")
ap.add_argument ("- c", "--classes", required = True,
help = "путь к файлу меток классов")
ap.add_argument ("- i", "--input", type = str, default = "",
help = "необязательный путь к видеофайлу")
args = vars (ap.parse_args ())
Начнем с импорта по строкам 2-6 . Для сегодняшнего урока вам необходимо установить OpenCV 4 и imutils. Посетите мои инструкции по установке opencv, чтобы установить OpenCV в вашей системе, если вы еще этого не сделали.
Строки 10-16 анализируют аргументы нашей командной строки:
-
--model: Путь к обученной модели распознавания человеческой активности. -
--classes: путь к файлу меток классов распознавания действий. -
--input: необязательный путь к вашему входному видеофайлу. Если этот аргумент не указан в командной строке, будет активирована ваша веб-камера.
Отсюда мы будем выполнять инициализацию:
# загружаем содержимое файла меток классов, затем определяем образец
# продолжительность (т.е.е., количество кадров для классификации) и размер выборки
# (т.е. пространственные размеры кадра)
КЛАССЫ = open (args ["классы"]). Read (). Strip (). Split ("\ n")
SAMPLE_DURATION = 16
SAMPLE_SIZE = 112
Строка 21 загружает наши метки классов из текстового файла.
Строки 22 и 23 определяют продолжительность выборки (то есть количество кадров для классификации) и размер выборки (то есть пространственные размеры кадра).
Затем мы загрузим и инициализируем нашу модель распознавания человеческой активности:
# загрузить модель распознавания человеческой активности
print ("[INFO] загрузка модели распознавания человеческой деятельности... ")
net = cv2.dnn.readNet (args ["модель"])
# получаем указатель на входной видеопоток
print ("[ИНФОРМАЦИЯ] доступ к видеопотоку ...")
vs = cv2.VideoCapture (args ["input"] if args ["input"] else 0)
Строка 27 использует модуль DNN OpenCV для чтения предварительно обученной модели распознавания человеческой активности PyTorch .
Строка 31 затем создает экземпляр нашего видеопотока с помощью видеофайла или веб-камеры.
Теперь мы готовы начать перебирать кадры и выполнять распознавание человеческой активности:
# цикл, пока мы явно не прервем его
в то время как True:
# инициализируем пакет кадров, который будет проходить через
# модель
кадры = []
# перебрать количество требуемых выборочных кадров
для i в диапазоне (0, SAMPLE_DURATION):
# читать кадр из видеопотока
(схвачено, рамка) = vs.читать()
# если кадр не был схвачен, значит, мы достигли конца
# видеопоток поэтому выходим из скрипта
если не схватили:
print ("[ИНФОРМАЦИЯ] из потока не читается фрейм - выход")
sys.exit (0)
# в противном случае фрейм был прочитан, поэтому измените его размер и добавьте в
# наш список фреймов
frame = imutils.resize (рамка, ширина = 400)
frames.append (кадр)
Строка 34 начинает цикл по нашим кадрам, где сначала мы инициализируем пакет из кадров , который будет передан через нейронную сеть ( Строка 37 ).
Отсюда, строк 40-53 заполняют пакет из кадров непосредственно из нашего видеопотока. Строка 52 изменяет размер каждого кадра до ширины из 400 пикселей, в то время как сохраняет соотношение сторон .
Давайте сконструируем наши blob входных фреймов, которые мы скоро пройдем через распознавание человеческой активности CNN:
# теперь, когда наш массив кадров заполнен, мы можем построить наш blob blob = cv2.dnn.blobFromImages (кадры, 1.0, (SAMPLE_SIZE, SAMPLE_SIZE), (114.7748, 107.7354, 99.4750), swapRB = True, обрезка = True) blob = np.transpose (blob, (1, 0, 2, 3)) blob = np.expand_dims (blob, axis = 0)
Строки 56-60 создают blob из нашего входного списка кадров .
Обратите внимание, что мы используем blobFromImages (т. Е. Множественное число) , а не функцию blobFromImage (т. Е. Единственное число) - причина в том, что мы создаем пакет из множественных изображений , которые нужно передать через сеть распознавания человеческой деятельности, что позволяет использовать пространственно-временную информацию.
Если бы вы вставили в код инструкцию print (blob.shape) , вы бы заметили, что blob имеет следующую размерность:
(1, 3, 16, 112, 112)
Давайте разберемся с этой размерностью еще немного:
-
1: Размер партии. Здесь у нас есть только одиночная точка данных , которая передается через сеть («точка данных» в этом контексте означает кадры N , которые будут переданы через сеть для получения единой классификации ). -
3: количество каналов во входных кадрах. -
16: общее количествокадроввBLOB-объектах. -
112(первое появление): высота фреймов. -
112(второе появление): ширина фреймов.
На этом этапе мы готовы выполнить логического вывода распознавания человеческой активности с последующим аннотированием кадра прогнозируемой меткой и отображением прогноза на нашем экране:
# передать BLOB-объект по сети, чтобы получить информацию о нашей человеческой деятельности
# прогноз распознавания
сеть.setInput (blob)
выходы = net.forward ()
label = КЛАССЫ [np.argmax (выходы)]
# перебрать наши рамки
для рамы в рамах:
# рисуем прогнозируемую активность на кадре
cv2.rectangle (кадр, (0, 0), (300, 40), (0, 0, 0), -1)
cv2.putText (кадр, метка, (10, 25), cv2.FONT_HERSHEY_SIMPLEX,
0,8, (255, 255, 255), 2)
# выводим рамку на наш экран
cv2.imshow ("Распознавание активности", рамка)
ключ = cv2.waitKey (1) & 0xFF
# если была нажата клавиша `q`, выйти из цикла
если ключ == ord ("q"):
перерыв
Строки 64 и 65 передают blob через сеть, получая список из выходных данных , предсказаний.
Затем мы берем метку самого высокого предсказания для большого двоичного объекта (, строка 66, ).
Используя метку , мы можем затем нарисовать прогноз для каждого кадра в списке кадров ( строк 69-73 ), отображая выходные кадры до тех пор, пока не будет нажата клавиша q , в которой мы сломать и выйти.
Альтернативная реализация человеческой деятельности с использованием структуры данных Deque
Внутри нашего распознавания человеческой деятельности из предыдущего раздела вы заметите следующие строки:
# цикл, пока мы явно не прервем его
в то время как True:
# инициализируем пакет кадров, который будет проходить через
# модель
кадры = []
# перебрать количество требуемых выборочных кадров
для i в диапазоне (0, SAMPLE_DURATION):
# читать кадр из видеопотока
(схвачено, рамка) = vs.читать()
# если кадр не был схвачен, значит, мы достигли конца
# видеопоток поэтому выходим из скрипта
если не схватили:
print ("[ИНФОРМАЦИЯ] из потока не читается фрейм - выход")
sys.exit (0)
# в противном случае фрейм был прочитан, поэтому измените его размер и добавьте в
# наш список фреймов
frame = imutils.resize (рамка, ширина = 400)
frames.append (кадр)
Эта реализация подразумевает, что:
- Всего мы прочитали
SAMPLE_DURATIONкадров из нашего входного видео. - Мы пропускаем эти кадры через нашу модель распознавания человеческой деятельности, чтобы получить результат.
- И затем мы читаем еще
SAMPLE_DURATIONкадров и повторяем процесс.
Таким образом, наша реализация — это , а не скользящее предсказание.
Вместо этого он просто берет образец кадров, классифицирует их и переходит к следующему пакету — любые кадры из предыдущего пакета отбрасываются.
Причина, по которой мы это делаем, — скорость .
Если мы классифицируем каждый отдельный фрейм, скрипту потребуется больше времени для запуска.
Тем не менее, использование прогнозирования скользящего кадра через структуру данных с двухсторонней очередью может привести к лучшим результатам, поскольку оно не отбрасывает все предыдущие кадры — прогнозирование скользящего кадра отбрасывает только самый старый кадр в списке, освобождая место для новейшая рама .
Чтобы увидеть, как это может вызвать проблему, связанную со скоростью вывода, предположим, что в видеофайле N кадров:
- Если мы делаем , используем предсказание скользящего кадра, мы выполняем
Nклассификаций, по одной для каждого кадра (разумеется, после заполнения структуры данныхdeque) - Если мы, , не используем прогнозирование с последовательным кадром, , нам нужно только выполнить
N / SAMPLE_DURATIONклассификаций, что значительно сокращает время, необходимое для обработки видеопотока .
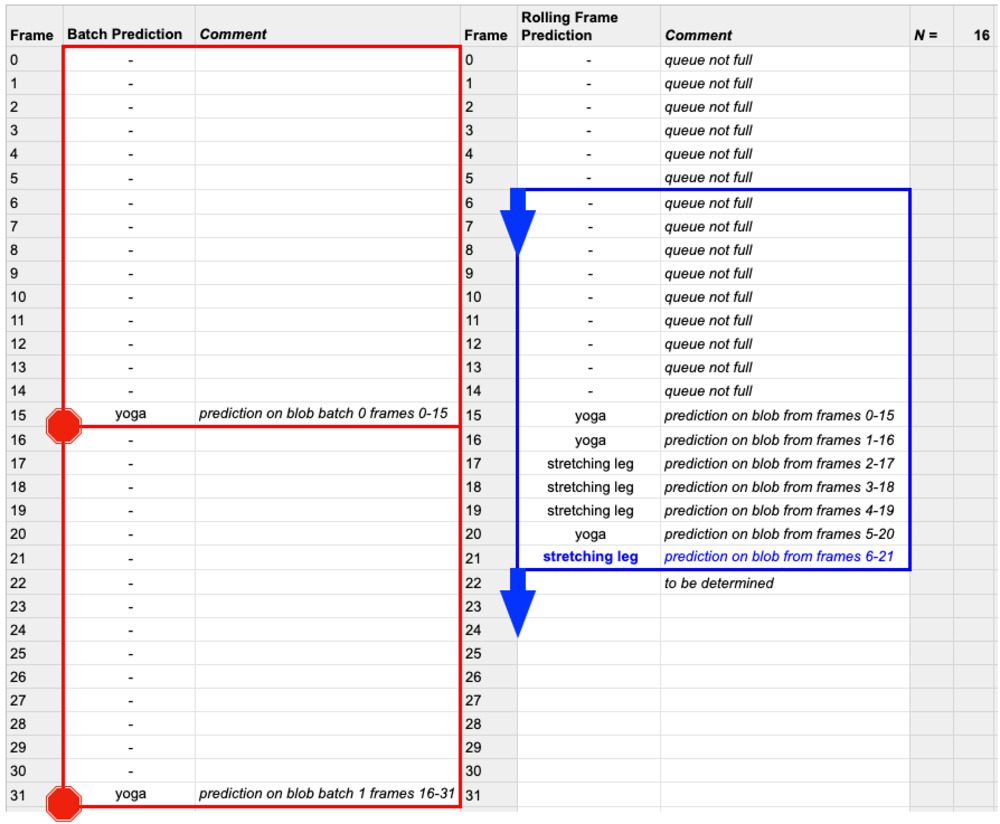 Рисунок 4: Прогнозирование со скользящим графиком ( синий ) использует полностью заполненное окно очереди FIFO для прогнозирования. Пакетное предсказание ( красный ) не «катится» от кадра к кадру. Скользящее прогнозирование требует большей вычислительной мощности, но приводит к лучшим результатам для распознавания человеческой активности с помощью OpenCV и глубокого обучения.
Рисунок 4: Прогнозирование со скользящим графиком ( синий ) использует полностью заполненное окно очереди FIFO для прогнозирования. Пакетное предсказание ( красный ) не «катится» от кадра к кадру. Скользящее прогнозирование требует большей вычислительной мощности, но приводит к лучшим результатам для распознавания человеческой активности с помощью OpenCV и глубокого обучения.
Учитывая, что модуль OpenCV dnn не поддерживает большинство графических процессоров (включая графические процессоры NVIDIA), я бы порекомендовал не использовать предсказание скользящего кадра для большинства приложений.
Тем не менее, внутри .zip-файла для сегодняшнего руководства (находится в разделе «Загрузки» сообщения) вы найдете файл с именем human_activity_reco_deque.py — этот файл содержит реализацию распознавания человеческой активности. что выполняет предсказание скользящего кадра.
Скрипт очень похож на предыдущий, но я включаю его сюда, чтобы вы могли поэкспериментировать:
# импортируем необходимые пакеты
из коллекций import deque
импортировать numpy как np
import argparse
импорт imutils
импорт cv2
# создать парсер аргументов и проанализировать аргументы
ap = argparse.ArgumentParser ()
ap.add_argument ("- m", "--model", required = True,
help = "путь к обученной модели распознавания человеческой активности")
ap.add_argument ("- c", "--classes", required = True,
help = "путь к файлу меток классов")
ap.add_argument ("- i", "--input", type = str, default = "",
help = "необязательный путь к видеофайлу")
args = vars (ap.parse_args ())
# загружаем содержимое файла меток классов, затем определяем образец
# продолжительность (т.е. # кадров для классификации) и размер выборки
# (т.е. пространственные размеры кадра)
CLASSES = open (args ["классы"]).read (). strip (). split ("\ n")
SAMPLE_DURATION = 16
SAMPLE_SIZE = 112
# инициализируем очередь кадров, используемую для хранения продолжительности скользящей выборки
Кол-во кадров - эта очередь автоматически выталкивает старые кадры и
# принять новые
frames = deque (maxlen = SAMPLE_DURATION)
# загрузить модель распознавания человеческой активности
print ("[ИНФОРМАЦИЯ] загрузка модели распознавания человеческой деятельности ...")
net = cv2.dnn.readNet (args ["модель"])
# получаем указатель на входной видеопоток
print ("[ИНФОРМАЦИЯ] доступ к видеопотоку ...")
vs = cv2.VideoCapture (args ["input"] if args ["input"] else 0)
Импорт такой же, за исключением встроенной в Python реализации deque из модуля коллекций (, строка 2, ).
В строке 28 мы инициализируем очередь кадров FIFO с максимальной длиной, равной длительности нашей выборки. Наша очередь «первым пришел - первым обслужен» (FIFO) автоматически выталкивает старые кадры и принимает новые. Мы выполним скользящий вывод для очереди кадров.
Все остальные строки выше такие же, поэтому давайте теперь проверим наш цикл обработки кадров:
# перебирать кадры из видеопотока
в то время как True:
# читать кадр из видеопотока
(схвачено, рамка) = vs.читать()
# если кадр не был схвачен, значит, мы достигли конца
# видеопоток, чтобы выйти из цикла
если не схватили:
print ("[ИНФОРМАЦИЯ] из потока не читается фрейм - выход")
перерыв
# изменить размер кадра (для ускорения обработки) и добавить
# кадр в нашу очередь
frame = imutils.resize (рамка, ширина = 400)
frames.append (кадр)
# если наша очередь не заполнена до размера выборки, вернемся к
# начало цикла и продолжить опрос / обработку кадров
если len (кадры) Строки 41-57 отличаются от нашего предыдущего скрипта.
Ранее мы выбирали пакет из кадров SAMPLE_DURATION и позже выполняли логический вывод для этого пакета.
В этом скрипте мы по-прежнему выполняем логический вывод в пакетном режиме; однако сейчас это прокатная партия . Разница в том, что мы добавляем кадры в нашу очередь FIFO на Строке 52 . Опять же, эта очередь имеет maxlen длительности нашей выборки, а заголовок очереди всегда будет текущим кадром нашего видеопотока. Как только очередь заполняется, старые кадры автоматически выталкиваются с реализацией deque FIFO.
Результатом этой скользящей реализации является то, что как только очередь будет заполнена, любой заданный кадр (за исключением самого первого кадра) будет «затронут» (то есть будет включен в скользящий пакет) более одного раза. Этот метод менее эффективен; однако это приводит к более точному распознаванию активности, особенно когда действия видео / сцены периодически меняются.
Строки 56 и 57 позволяют нашей очереди кадров заполняться (т.е. до 16 кадров, как показано на рис. 4 , синий ) до выполнения любого логического вывода.
Когда очередь заполнится, мы выполним скользящий прогноз распознавания человеческой активности:
# теперь, когда наш массив кадров заполнен, мы можем построить наш blob
blob = cv2.dnn.blobFromImages (кадры, 1.0,
(SAMPLE_SIZE, SAMPLE_SIZE), (114.7748, 107.7354, 99.4750),
swapRB = True, обрезка = True)
blob = np.transpose (blob, (1, 0, 2, 3))
blob = np.expand_dims (blob, axis = 0)
# передать BLOB-объект по сети, чтобы узнать о нашей человеческой деятельности
# прогноз распознавания
net.setInput (большой двоичный объект)
выходы = нетто.вперед()
label = КЛАССЫ [np.argmax (выходы)]
# рисуем прогнозируемую активность на кадре
cv2.rectangle (кадр, (0, 0), (300, 40), (0, 0, 0), -1)
cv2.putText (кадр, метка, (10, 25), cv2.FONT_HERSHEY_SIMPLEX,
0,8, (255, 255, 255), 2)
# выводим рамку на наш экран
cv2.imshow ("Распознавание активности", рамка)
ключ = cv2.waitKey (1) & 0xFF
# если была нажата клавиша `q`, выйти из цикла
если ключ == ord ("q"):
перерыв
Этот блок кода содержит строки кода, идентичные нашему предыдущему сценарию.Здесь мы:
- Создайте
BLOB-объекта из нашей очереди из кадров . - Выполните логический вывод и получите прогноз с наибольшей вероятностью для большого двоичного объекта
. - Аннотировать и отображать текущий кадр
с полученной меткой скользящего среднего распознавания человеческой активности. - Выход при нажатии клавиши
q .
Результаты распознавания человеческой деятельности
Давайте посмотрим на результаты нашего кода распознавания человеческой деятельности в действии!
Используйте раздел «Загрузки» этого руководства, чтобы загрузить предварительно обученную модель распознавания человеческой активности, исходный код Python + OpenCV и пример демонстрационного видео.
Оттуда откройте терминал и выполните следующую команду:
$ python human_activity_reco_deque.py --model resnet-34_kinetics.onnx \
--classes action_recognition_kinetics.txt \
--input example_activities.mp4
[ИНФОРМАЦИЯ] загрузка модели распознавания человеческой активности ...
[INFO] доступ к видеопотоку ...
Обратите внимание, что для нашей модели распознавания человеческой деятельности требуется не менее OpenCV 4.1.2.
Если вы используете более старую версию OpenCV, вы получите следующую ошибку:
net = cv2.dnn.readNet (args ["модель"])
cv2.error: OpenCV (4.1.0) /Users/adrian/build/skvark/opencv-python/opencv/modules/dnn/src/onnx/onnx_importer.cpp:245: ошибка: (-215: сбой утверждения) attribute_proto. ints_size () == 2 в функции getLayerParams
Если вы получили эту ошибку, вам необходимо обновить установку OpenCV до , по крайней мере, до OpenCV 4.1.2.
Ниже приведен пример нашей модели, которая правильно маркирует входной видеоклип как «йога»
Обратите внимание, как модель колеблется между «йога», и «вытягивание ноги», - оба технически правильны здесь, так как в положении собаки вниз вы по определению занимаетесь йогой, но также вытягиваете ноги в то же время.
В следующем примере наша модель распознавания человеческой активности правильно предсказывает это видео как «скейтбординг» :
Вы можете понять, почему модель также предсказала «паркур» - фигурист прыгает через перила, что похоже на действие, которое может выполнить паркурист.
Кто-нибудь голоден?
Если да, то вас может заинтересовать «приготовление пиццы» :
Но перед едой убедитесь, что вы «вымыли руки» , прежде чем садиться есть:
Если вы решите попробовать «пить пиво» , вам лучше посмотреть, сколько вы пьете - бармен может вас отрезать:
Как видите, наша модель распознавания человеческой деятельности, хотя и не идеальна, все же работает достаточно хорошо, учитывая простоту нашей техники (преобразование ResNet для обработки входных данных 3D в отличие от 2D).
Распознавание человеческой деятельности - - далека от , но с помощью глубокого обучения и сверточных нейронных сетей мы добиваемся больших успехов.
Кредиты
Видео на этой странице, включая те, что находятся в файле example_activities.mp4 , найденном в «Загрузках» этого руководства, взяты из следующих источников:
Сводка
В этом руководстве вы узнали, как выполнять распознавание человеческой активности с помощью OpenCV и глубокого обучения.
Для выполнения этой задачи мы использовали модель распознавания человеческой активности, предварительно обученную на наборе данных Kinetics, которая включает 400-700 человеческих действий (в зависимости от того, какую версию набора данных вы используете) и более 300 000 видеоклипов.
Модель, которую мы использовали, была ResNet, но с изюминкой - архитектура модели была изменена для использования трехмерных ядер, а не стандартных 2D-фильтров, что позволило модели включать временной компонент для распознавания активности.
Подробнее о модели можно прочитать в Hara et al.Статья 2018, Могут ли пространственно-временные 3D CNN повторить историю 2D CNN и ImageNet?
Наконец, мы реализовали распознавание человеческой активности с использованием OpenCV и реализации PyTorch Хара и др., Которую мы загрузили через модуль OpenCV dnn .
Основываясь на наших результатах, мы видим, что наша модель распознавания человеческой активности, хотя и не идеальна, работает достаточно хорошо!
Чтобы загрузить исходный код и предварительно обученную модель распознавания человеческой активности (и получать уведомления, когда будущие учебные пособия будут опубликованы здесь, на PyImageSearch), просто введите свой адрес электронной почты в форму ниже!

Загрузите исходный код и БЕСПЛАТНОЕ 17-страничное руководство по ресурсам
Введите свой адрес электронной почты ниже, чтобы получить.zip кода и БЕСПЛАТНОЕ 17-страничное руководство по ресурсам по компьютерному зрению, OpenCV и глубокому обучению. Внутри вы найдете мои тщательно отобранные учебники, книги, курсы и библиотеки, которые помогут вам освоить CV и DL!
.
Человеческое действие и признание деятельности
Расширяемое графическое моделирование действий человека на основе данных на основе основных положений . В этой статье представлена графическая модель для обучения и распознавания человеческих действий. В частности, мы предлагаем кодировать действия в ориентированном взвешенном графе, называемом графом действий, где узлы графа представляют собой заметные позы, которые используются для характеристики действий и являются общими для всех действий. Вес между двумя узлами измеряет вероятность перехода между двумя положениями, представленными двумя узлами.Действие кодируется как один или несколько путей в графе действий. Выдающиеся позы моделируются с использованием моделей гауссовой смеси (GMM). И основные позы, и граф действий автоматически изучаются из обучающих выборок с помощью неконтролируемой кластеризации и алгоритма ожидания и максимизации (EM). Предлагаемый граф действий не только выполняет эффективное и надежное распознавание действий, но также может быть эффективно расширен за счет новых действий. Также предлагается алгоритм для добавления нового действия в обученный граф действий без ущерба для существующего графа действий.Обширные эксперименты с широко используемыми и сложными наборами данных подтвердили производительность предложенных методов, их устойчивость к шуму и точкам зрения, их надежность по различным предметам и наборам данных, а также эффективность алгоритма для обучения новым действиям.
Распознавание действий на основе набора 3D-очков . В этой статье представлен метод распознавания действий человека по последовательностям карт глубины. В частности, мы используем граф действий для явного моделирования динамики действий и набор трехмерных точек для характеристики набора значимых поз, которые соответствуют узлам в графе действий.Кроме того, мы предлагаем простую, но эффективную схему выборки на основе проекций для выборки набора трехмерных точек с карт глубины. Экспериментальные результаты показали, что точность распознавания более 90% была достигнута при выборке только около 1% трехмерных точек с карт глубины. По сравнению с распознаванием на основе 2D-силуэта ошибки распознавания сократились вдвое. Кроме того, мы демонстрируем возможности модели положения «мешок точек» для устранения окклюзий посредством моделирования.
Распознавание действий с использованием комбинации категорийных компонентов и локальных моделей для видеонаблюдения .В этой статье представлен новый подход к автоматическому распознаванию человеческой деятельности для приложений видеонаблюдения. Мы предлагаем представить деятельность в виде комбинации компонентов категорий и продемонстрировать, что этот подход предлагает гибкость для добавления новых действий в систему и возможность решения проблемы построения моделей для действий, для которых отсутствуют данные для обучения. Для повышения точности распознавания также предлагается алгоритм распознавания на основе уверенного кадра, в котором видеокадры с высокой степенью достоверности для распознавания активности используются в качестве специализированной локальной модели, помогающей классифицировать оставшиеся видеокадры.Результаты экспериментов показывают эффективность предложенного подхода.
Обнаружение групповых событий с различным количеством членов группы для видеонаблюдения . В этой статье представлен новый подход к автоматическому распознаванию групповых действий для приложений видеонаблюдения. Мы предлагаем использовать представителя группы для обработки распознавания с различным количеством членов группы и использовать асинхронную скрытую марковскую модель (AHMM) для моделирования отношений между людьми.Кроме того, мы предлагаем алгоритм обнаружения групповой активности, который может обрабатывать как симметричные, так и асимметричные групповые действия, и демонстрируем, что этот подход позволяет обнаруживать иерархические взаимодействия между людьми. Результаты экспериментов показывают эффективность нашего подхода.
.
