Надежность теста
Надежность теста один из критериев качества теста, относящийся к точности психологических измерений. Чем больше Надежность теста, тем относительно свободнее он от погрешностей измерения. Надежность теста рассматривается при одном подходе: как устойчивость (стабильность) результатов при повторном тестировании; при другом, как проявление степени эквивалентности двух одинаковых по форме и цели (параллельных) тестов.
Надежность теста
Надежность теста — фундаментальная характеристика теста, которая показывает в какой степени стабильны результаты тестирования при неоднократном обследовании. Надежность теста может определяться путем повторного тестирования (через строго определенный отрезок времени) и вычисления коэффициента корреляции между результатами первого и повторного тестирования. Надежность теста может определяться и путем тестирования с помощью нескольких вариантов одного и того же теста, деления теста на две половины и т.д. Надежность результатов тестирования зависит не только от качества самого теста, но и от процедуры проведения тестирования (она должна быть абсолютно идентичной в первом и во втором случае), социально-психологической однородности выборки (н. т. будет различной для детей, мужчин, женщин, солдат первого года – службы, старослужащих солдат и т.д.). И может получиться, что будучи надежным для одной группы людей, тест окажется ненадежным для другой, результаты тестирования в последнем случае будут неверны. Таким образом, н.т., выражая степень неточности, возможность ошибки, возникающей неизбежно при любом тестировании, заставляет искать пути уменьшения этой ошибки, более конкретного, целеустремленного применения теста. Надежность лучших тестов составляет 0,8 — 0,9.
Надежность эксперимента
устойчивость результатов эксперимента при его проведении второй, третий, четвертый и т.д. раз.
Добиться объективности психологического теста можно при выполнении следующих условий:
1) единообразие процедуры проведения теста для получения сравнимых с нормой (см. ниже) результатов;
2) единообразие оценки выполнения теста;
3) определение нормы выполнения теста для сопоставления с ними показателей, полученных в результате обработки данных тестирования (см. здесь «третий этап стандартизации»).
Эти три условия называют этапами стандартизации психологического теста.
Этапы стандартизации
На этапе разработки теста, а также любого другого метода проводится процедура стандартизации, которая включает три этапа.
Первый этап стандартизации психологического теста состоит в создании единообразной процедуры тестирования. Она включает определение следующих моментов диагностической ситуации:
1) условия тестирования (помещение, освещение и др. внешние факторы). Очевидно, что объем кратковременной памяти лучше измерять (например, с помощью субтеста повторения цифровых рядов в тесте Векслера), когда нет внешних раздражителей, таких как посторонние звуки, голоса и т.д.
2) Содержание инструкции и особенности ее предъявления (тон голоса, паузы, скорость речи и т.д.). Например, в тесте «10 слов» каждое слово должно предъявляться через определенный интервал времени в секундах.
3) Наличие стандартного стимульного материала. Например, достоверность полученных результатов существенно зависит от того, предлагаются ли респонденту изготовленные самодельные карты Г.Роршаха или стандартные — с определенной цветовой гаммой и цветовыми оттенками.
4) Временные ограничения выполнения данного теста. Например, для выполнения теста Равена взрослому респонденту дается 20 минут.
5) Стандартный бланк для выполнения данного теста. Использование стандартного бланка облегчает процедуру обработки.
6) Учет влияния ситуационных переменных на процесс и результат тестирования. Под переменными подразумевается состояние испытуемого (усталость, перенапряжение и т.д.), нестандартные условия тестирования (плохое освещение, отсутствие вентиляции и др.), прерывание тестирования.
7) Учет влияния поведения диагноста на процесс и результат тестирования. Например, одобрительно-поощряющее поведение экспериментатора во время тестирования может восприниматься респондентом как подсказка «правильного ответа» и др.
8) Учет влияния опыта респондента в тестировании. Естественно, что респондент, который уже не в первый раз проходит процедуру тестирования, преодолел чувство неизвестности и выработал определенное отношение к тестовой ситуации. Например, если респондент уже выполнял тест Равена, то, скорее всего, не стоит предлагать ему его во второй раз.
Второй этап стандартизации психологического теста состоит в создании единообразной оценки выполнения теста: стандартной интерпретации полученных результатов и предварительной стандартной обработки. Этот этап предполагает также сравнение полученных показателей с нормой выполнения этого теста для данного возраста (например, в тестах интеллекта), пола и т.д. (см. ниже).
Третий этап стандартизации психологического теста состоит в определении норм выполнения теста.
Нормы разрабатываются для различных возрастов, профессий, полов и др. Вот некоторые из существующих видов норм:
Школьные нормы — разрабатываются на основе тестов школьных достижений или тестов школьных способностей. Они устанавливаются для каждой школьной ступени и действуют на всей территории страны.
Профессиональные нормы устанавливаются на основе тестов для разных профессиональных групп (например, механиков разного профиля, машинисток и др.).
Локальные нормы устанавливаются и применяются для узких категорий людей, отличающихся наличием общего- признака — возраста, пола, географического района, социо-экономического статуса и др. Например, для теста Векслера на интеллект нормы ограничены возрастными рамками.
Национальные нормы разрабатываются для представителей данной народности, нации, страны в целом. Необходимость таких норм определяется конкретной культурой, моральными требованиями и традициями каждой нации.
Наличие нормативных данных (норм) в стандартизованных методах психодиагностики является их существенной характеристикой.
НАДЁЖНОСТЬ ТЕСТА — это… Что такое НАДЁЖНОСТЬ ТЕСТА?
- НАДЁЖНОСТЬ ТЕСТА
НАДЁЖНОСТЬ ТЕСТА.
Показатель точности педагогического измерения и устойчивости результатов тестирования к воздействию посторонних или случайных факторов. Тест считается надежным, если он дает одни и те же (или очень близкие) показатели для каждого испытуемого при повторном тестировании. При этом необходимо, чтобы сами испытуемые не изменили свой уровень подготовки перед вторым тестированием, а их мотивация к получению наилучших результатов осталась прежней. Надежность связана с понятием стандартной ошибки педагогического измерения: чем выше надежность, тем меньше стандартная ошибка измерения. Существует много способов определения Н. т. Один из способов – нахождение коэффициента корреляции между двумя параллельными тестами на одной и той же выборке студентов. При итоговой и поэтапной аттестации студентов желательно получить высокую Н. т. В этом случае Н. т. определяется постоянством результатов, т. е. соответствием между результатами разных вариантов теста из данной области содержания для каждого испытуемого.
Новый словарь методических терминов и понятий (теория и практика обучения языкам). — М.: Издательство ИКАР.
Э. Г. Азимов, А. Н. Щукин.
2009.
- НАГЛЯДНЫЕ ПОСОБИЯ ВИЗУАЛЬНЫЕ
- НАЛИЧНОСТЬ
Смотреть что такое «НАДЁЖНОСТЬ ТЕСТА» в других словарях:
Надёжность пунктов — – надёжность теста, определяемая степенью, в которой разные пункты теста измеряют одни и те же конструкты (в данном случае качества или черты) … Энциклопедический словарь по психологии и педагогике
Надёжность взаимозаменяемых форм — – надёжность теста, определяется близкими результатами, которые получены посредством использования параллельных или эквивалентных тестов … Энциклопедический словарь по психологии и педагогике
Надёжность психологического теста — Надёжностью называется один из критериев качества теста, его устойчивость по отношению к погрешностям измерения. Различают два вида надёжности надёжность как устойчивость и надёжность как внутреннюю согласованность. Содержание 1 Надёжность… … Википедия
Надёжность ретестовая — – метод определения надёжности теста путём применения его два раза (или более) с одним и тем же человеком и последующего вычисления коэффициента надёжности между соответствующими значениями. Предполагается, что период времени между тестированиями … Энциклопедический словарь по психологии и педагогике
Надёжности коэффициент — – в статистике – коэффициент корреляции, выражающий степень связи между двумя наборами значений, причём эти наборы значений представляют собой результаты двух сеансов тестирования одним и тем же инструментом. Этот коэффициент используется затем в … Энциклопедический словарь по психологии и педагогике
Надежность психологического теста — Надёжностью называется один из критериев качества теста, его устойчивость по отношению к погрешностям измерения. Различают два вида надёжности надёжность как устойчивость и надёжность как внутреннюю согласованность. Содержание 1 Надёжность как… … Википедия
Контроль в обучении — абитуриент тест, айзенка тест, анализ ошибок, анализ речи компьютером, анализ урока, анкета, анкетирование, баллы оценочные, валидность теста, векслера тест, гиперкоррекция, грамматико морфологические ошибки, грамматико синтаксические ошибки,… … Новый словарь методических терминов и понятий (теория и практика обучения языкам)
Плетизмография полового члена — (пенильная плетизмография, фаллометрия) метод, которым измеряется изменение в кровоснабжении полового члена.[1] Обычно о кровотоке в члене судят по изменению окружности или объёма полового члена. Метод используется при расследовании… … Википедия
Преждевременное излитие околоплодных вод — Преждевременный разрыв плодных оболочек (ПРПО) – это осложнение беременности, характеризующееся нарушением целостности оболочек плодного пузыря и излитием околоплодных вод (до начала родовой деятельности) на любом сроке беременности. Часто воды… … Википедия
Джобс, Стив — Стив Джобс Steve Jobs … Википедия
Надёжность психологического теста — это… Что такое Надёжность психологического теста?
Надёжностью называется один из критериев качества теста, его устойчивость по отношению к погрешностям измерения. Различают два вида надёжности — надёжность как устойчивость и надёжность как внутреннюю согласованность.
Надёжность как устойчивость
Устойчивость результатов теста или ретестовая надежность (англ — test-retest reliability) – возможность получения одинаковых результатов у испытуемых в различных случаях.
Устойчивость определяется с помощью повторного тестирования (ретеста):
В данном методе предлагается провести несколько замеров с некоторым промежутком времени (от недели до года) одним и тем же тестом. Если корреляция между результатами различных замеров будет высокой, следовательно, тест достаточно надежный. Наименьшим удовлетворительным значением для ретестовой надежности является 0,5. Однако надежность не всех тестов можно проверять этим методом, так как оцениваемое качество, явление или эффект могут быть сами по себе нестабильны (например, наше настроение, которое может меняться от одного замера к следующему). Еще один недостаток повторного тестирования – это эффект привыкания. Испытуемые уже знакомы с этим тестом, а может быть, даже помнят большую часть своих ответов после предыдущего заполнения.
В связи с выше сказанным применяется исследование надежности психодиагностических методик с использованием параллельных форм, при которых конструируются эквивалентные или параллельные наборы заданий. При этом испытуемые выполняют совершенно другой тест при аналогичных условиях. Однако имеются трудности в доказательстве того, что обе формы являются действительно эквивалентными. Несмотря на это, на практике параллельные формы тестов оказываются полезными в установлении надежности тестов.
Надёжность как внутренняя согласованность
Внутренняя согласованность(англ. — internal consistency) определяется связью каждого конкретного элемента теста с общим результатом, тем, насколько каждый элемент входит в противоречие с остальными, насколько каждый отдельный вопрос измеряет признак, на который направлен весь тест. Чаще всего тесты, разрабатываются таким образом, чтобы у них была высокая степень внутренней согласованности, а связи с тем, что если одна переменная измеряется частью теста, то тогда в других частях, если они не согласованы с первой, эта же переменная измеряться не может. Таким образом, чтобы тест был валидным, необходимо, чтобы он был согласован.
Однако существует и противоположная точка зрения. Кэттелл говорит о том, что высокая внутренняя согласованность на самом деле является противоположностью валидности: каждый вопрос должен затрагивать меньшую область или иметь более узкое значение, чем критерий, подвергающийся измерению. Если все вопросы являются согласованными в высокой степени, они сильно коррелируют, и, следовательно, надежный тест будет измерять только лишь сравнительно «узкую» переменную с малыми отклонениями. По рассуждениям Кэттелла, максимум валидности существует, когда все задания теста не коррелируют друг с другом, а каждое из них имеет положительную корреляцию с критерием. Однако, такой тест будет характеризоваться низкой надежностью по внутренней согласованности.
Для проверки внутренней согласованности применяются:
- Метод расщепления или метод автономных частей
- Метод эквивалентных бланков
- Альфа Кронбаха
Метод расщепления (Split-half reliability)
Этот метод заключается в расщеплении/разделении теста на две равные части (например, четные и нечетные вопросы, первая и вторая половина), а затем находится корреляция между ними. Если корреляция высокая, тест можно считать надежным.
Метод эквивалентных бланков
МЭБ состоит в применении двух сопоставимых друг с другом форм теста для большой выборки (например, формы L и M для измерения в шкале интеллекта Стэнфорда-Бине) Результаты, полученные при выполнении двух форм, сравнивают и высчитывают корреляцию. Если коэффициент корреляции высокий, следовательно, тест надежен. Недостаток этого метода в том, что он подразумевает такой длительный и трудоемкий процесс, как создание двух эквивалентных форм.
Альфа Кронбаха
В этом методе, предложенном Ли Кронбахом, сравнивается разброс каждого элемента с общим разбросом всей шкалы. Если разброс результатов теста меньше, чем разброс результатов для каждого отдельного вопроса, следовательно, каждый отдельный вопрос направлен на исследование одного и того же общего основания. Они вырабатывают значение, которое можно считать истинным. Если такое значение выработать нельзя, то есть получается случайный разброс при ответе на вопросы, тест не надежен и коэффициент альфа Кронбаха будет равен 0. Если же все вопросы измеряют один и тот же признак, то тест надежен и коэффициент альфа Кронбаха в этом случае будет равен 1.
Вычисление Кронбаха
Кронбаха определяется как
,
где — число элементов в шкале, — дисперсия общего тестового балла, и — дисперсия элемента .
Альтернативный способ вычисления выглядит следующим способом:
где N — число элементов в шкале, — средняя дисперсия для выборки, — среднее значение для всех ковариаций между компонентами выборки.
В настоящее время Кронбаха считают при помощи SPSS, STATISTICA и других современных статистических пакетов, возможно и при помощи Microsoft Excel
Значение Кронбаха
Альфа Кронбаха в целом будет возрастать по мере увеличения взаимных корреляций переменных, и, поэтому, считается маркёром внутренней согласованности оценки достоверности результатов тестов. Так как максимальное взаимные корреляции между переменными по всем пунктам присутствуют, если измеряется одно и то же, альфа Кронбаха косвенно указывает на степень того, насколько все пункты измеряют одно и то же. Таким образом, альфа наиболее целесообразно использовать, когда все пункты направлены на измерение одного и того же явления, свойства, феномена. Однако, следует заметить, что высокое значение коэффициента указывает на наличие общего основания у набора вопросов, но не говорит о том, что за ними стоит один единственный фактор — одномерность шкалы следует подтверждать дополнительными методами Когда измеряют гетерогенную структуру, альфа Кронбаха часто будет низким. Таким образом, альфа не подходит для оценки надежности умышленно гетерогенной инструментов (например, для оригинала MMPI, в данном случае имеет смысл проводить отдельные измерения для каждой шкалы).
Считается, что профессионально разработанные тесты должны иметь внутреннюю согласованность на уровне не менее 0.90.
Коэффициент альфа может применяться и для решения другого типа задач. Так, с его помощью можно измерять степень согласованности экспертов, оценивающих тот или иной объект, стабильность данных при многократных измерениях и т.д
Теоретическое основание Кронбаха
Альфа Кронбаха может быть рассмотрено как расширение Кьюдера-Ричардсона-20 , которая является эквивалентом для работы с дихотомиями или переменными, принимающих только два значения (например, ответы истинно/ложно).
Α Кронбаха теоретически связана с формулой прогнозирования Спирмана-Брауна. И обе эти формулы вытекают из классической теорией теста, заключающийся в том, что достоверность результатов тестирования может быть выражена как отношение дисперсий истинной и общей оценок (ошибки и истинной оценки).
См. также
Помимо надежности тестов, есть так же надежность наблюдения – межнаблюдательская надежность. МН – это процент совпадения результатов наблюдения экспертов друг с другом.
Надежность и валидность
Надежность показывает, что результаты проводимого исследования близки к истине, а валидность показывает, что результаты действительно относятся к тому явлению, которое изучается исследователем. Валидное исследование автоматически является надежным, однако обратное следствие не обязательно. Надежное исследование может и не быть валидным.
Литература
Пол Клайн. «Справочное руководство по конструированию тестов», Киев, 1994.
Ссылки
Надежность психологического теста — это… Что такое Надежность психологического теста?
Надёжностью называется один из критериев качества теста, его устойчивость по отношению к погрешностям измерения. Различают два вида надёжности — надёжность как устойчивость и надёжность как внутреннюю согласованность.
Надёжность как устойчивость
Устойчивость результатов теста или ретестовая надежность (англ — test-retest reliability) – возможность получения одинаковых результатов у испытуемых в различных случаях.
Устойчивость определяется с помощью повторного тестирования (ретеста):
В данном методе предлагается провести несколько замеров с некоторым промежутком времени (от недели до года) одним и тем же тестом. Если корреляция между результатами различных замеров будет высокой, следовательно, тест достаточно надежный. Наименьшим удовлетворительным значением для ретестовой надежности является 0,7. Однако надежность не всех тестов можно проверять этим методом, так как оцениваемое качество, явление или эффект могут быть сами по себе нестабильны (например, наше настроение, которое может меняться от одного замера к следующему). Еще один недостаток повторного тестирования – это эффект привыкания. Испытуемые уже знакомы с этим тестом, а может быть, даже помнят большую часть своих ответов после предыдущего заполнения.
В связи с выше сказанным возможно исследование надежности психодиагностических методик с использованием параллельных форм, при которых конструируются эквивалентные или параллельные наборы заданий. Получается, что испытуемые выполняют совершенно другой тест при аналогичных условиях. Однако, имеются трудности в доказательстве того, что обе формы являются действительно эквивалентными. Несмотря на это, на практике параллельные формы тестов оказываются полезными в установлении надежности тестов.
Надёжность как внутренняя согласованность
Внутренняя согласованность(англ. — self-consistent) определяется связью каждого конкретного элемента теста с общим результатом, тем, насколько каждый элемент входит в противоречие с остальными, насколько каждый отдельный вопрос измеряет признак, на который направлен весь тест. Чаще всего тесты, разрабатываются таким образом, чтобы у них была высокая степень внутренней согласованности, а связи с тем, что если одна переменная измеряется частью теста, то тогда в других частях, если они не согласованы с первой, эта же переменная измеряться не может. Таким образом, чтобы тест был валидным, необходимо, чтобы он был согласован.
Однако существует и противоположная точка зрения. Кэттелл говорит о том, что высокая внутренняя согласованность на самом деле является противоположностью валидности: каждый вопрос должен затрагивать меньшую область или иметь более узкое значение, чем критерий, подвергающийся измерению. Если все вопросы являются согласованными в высокой степени, они сильно коррелируют, и, следовательно, надежный тест будет измерять только лишь сравнительно «узкую» переменную с малыми отклонениями. По рассуждениям Кэттелла, максимум валидности существует, когда все задания теста не коррелируют друг с другом, а каждое из них имеет положительную корреляцию с критерием. Однако, такой тест будет характеризоваться низкой надежностью по внутренней согласованности.
Для проверки внутренней согласованности применяются:
- Метод расщепления или метод автономных частей
- Метод эквивалентных бланков
- Альфа Кронбаха
- Метод расщепления (Split-half reliability)
Этот метод заключается в расщеплении/разделении теста на две равные части (например, четные и нечетные вопросы, первая и вторая половина), а затем находится корреляция между ними. Если корреляция высокая, тест можно считать надежным.
- Метод эквивалентных бланков
МЭБ состоит в применении двух сопоставимых друг с другом форм теста для большой выборки (например, формы L и M для измерения в шкале интеллекта Стэнфорда-Бине) Результаты, полученные при выполнении двух форм, сравнивают и высчитывают корреляцию. Если коэффициент корреляции высокий, следовательно, тест надежен. Недостаток этого метода в том, что он подразумевает такой длительный и трудоемкий процесс, как создание двух эквивалентных форм.
- Альфа Кронбаха
В этом методе, предложенном Ли Кронбахом, сравнивается разброс каждого элемента с общим разбросом всей шкалы. Если разброс результатов теста меньше, чем разброс результатов для каждого отдельного вопроса, следовательно, каждый отдельный вопрос направлен на исследование одного и того же признака, свойства или явления. Они вырабатывают значение, которое можно считать истинным. Если такое значение выработать нельзя, то есть получается случайный разброс при ответе на вопросы, тест не надежен и коэффициент альфа Кронбаха будет равен 0. Если же все вопросы измеряют один и тот же признак, то тест надежен и коэффициент альфа Кронбаха в этом случае будет равен 1.
α Кронбаха определяется как
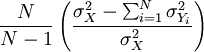 ,
,
где N — число элементов в шкале, 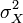 — дисперсия общего тестового балла, и
— дисперсия общего тестового балла, и 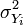 — дисперсия элемента i.
— дисперсия элемента i.
См. также
Помимо надежности тестов, есть так же надежность наблюдения – межнаблюдательская надежность. МН – это процент совпадения результатов наблюдения экспертов друг с другом.
Надежность и валидность
Надежность показывает, что результаты проводимого исследования близки к истине, а валидность показывает, что результаты действительно относятся к тому явлению, которое изучается исследователем. Валидное исследование автоматически является надежным, однако обратное следствие не обязательно. Надежное исследование может и не быть валидным.
Литература
Пол Клайн. «Справочное руководство по конструированию тестов», Киев, 1994.
Wikimedia Foundation.
2010.
Надёжность психологического теста — Википедия
Надёжностью называется один из критериев качества теста, его устойчивость по отношению к погрешностям измерения. Различают два вида надёжности — надёжность как устойчивость и надёжность как внутреннюю согласованность.
Надёжность как устойчивость
Устойчивость результатов теста или ретестовая надежность (англ — test-retest reliability) — возможность получения одинаковых результатов у испытуемых в различных случаях.
Устойчивость определяется с помощью повторного тестирования (ретеста):
В данном методе предлагается провести несколько замеров с некоторым промежутком времени (от недели до года) одним и тем же тестом. Если корреляция между результатами различных замеров будет высокой, следовательно, тест достаточно надежный. Наименьшим удовлетворительным значением для ретестовой надежности является 0.76.
Однако надежность не всех тестов можно проверять этим методом, так как оцениваемое качество, явление или эффект могут быть сами по себе нестабильны (например, наше настроение, которое может меняться от одного замера к следующему). Ещё один недостаток повторного тестирования — это эффект привыкания. Испытуемые уже знакомы с этим тестом, а может быть, даже помнят большую часть своих ответов после предыдущего заполнения.
В связи с выше сказанным применяется исследование надежности психодиагностических методик с использованием параллельных форм, при которых конструируются эквивалентные или параллельные наборы заданий. При этом испытуемые выполняют совершенно другой тест при аналогичных условиях. Однако имеются трудности в доказательстве того, что обе формы являются действительно эквивалентными. Несмотря на это, на практике параллельные формы тестов оказываются полезными в установлении надежности тестов.
Надёжность как внутренняя согласованность
Внутренняя согласованность(англ. — internal consistency) определяется связью каждого конкретного элемента теста с общим результатом, тем, насколько каждый элемент входит в противоречие с остальными, насколько каждый отдельный вопрос измеряет признак, на который направлен весь тест.
Чаще всего тесты разрабатываются таким образом, чтобы у них была высокая степень внутренней согласованности, а связи с тем, что если одна переменная измеряется частью теста, то тогда в других частях, если они не согласованы с первой, эта же переменная измеряться не может.
Таким образом, чтобы тест был валидным, необходимо, чтобы он был согласован.
Однако существует и противоположная точка зрения. Кэттелл говорит о том, что высокая внутренняя согласованность на самом деле является противоположностью валидности: каждый вопрос должен затрагивать меньшую область или иметь более узкое значение, чем критерий, подвергающийся измерению. Если все вопросы являются согласованными в высокой степени, они сильно коррелируют, и, следовательно, надежный тест будет измерять только лишь сравнительно «узкую» переменную с малыми отклонениями. По рассуждениям Кэттелла, максимум валидности существует, когда все задания теста не коррелируют друг с другом, а каждое из них имеет положительную корреляцию с критерием. Однако, такой тест будет характеризоваться низкой надежностью по внутренней согласованности.
Для проверки внутренней согласованности применяются:
- Метод расщепления или метод автономных частей
- Метод эквивалентных бланков
- Альфа Кронбаха
Метод расщепления (Split-half reliability)
Этот метод заключается в расщеплении/разделении теста на две равные части (например, четные и нечетные вопросы, первая и вторая половина), а затем находится корреляция между ними. Если корреляция высокая, тест можно считать надежным.
Метод эквивалентных бланков
МЭБ состоит в применении двух сопоставимых друг с другом форм теста для большой выборки (например, формы L и M для измерения в шкале интеллекта Стэнфорда-Бине)
Результаты, полученные при выполнении двух форм, сравнивают и высчитывают корреляцию. Если коэффициент корреляции высокий, следовательно, тест надежен. Недостаток этого метода в том, что он подразумевает такой длительный и трудоемкий процесс, как создание двух эквивалентных форм.
Метод альфа Кронбаха
В этом методе, предложенном Ли Кронбахом, сравнивается разброс каждого элемента с общим разбросом всей шкалы. Если разброс результатов теста меньше, чем разброс результатов для каждого отдельного вопроса, следовательно, каждый отдельный вопрос направлен на исследование одного и того же общего основания. Они вырабатывают значение, которое можно считать истинным. Если такое значение выработать нельзя, то есть получается случайный разброс при ответе на вопросы, тест не надежен и коэффициент альфа Кронбаха будет равен 0. Если же все вопросы измеряют один и тот же признак, то тест надежен и коэффициент альфа Кронбаха в этом случае будет равен 1.
Вычисление α{\displaystyle \alpha } Кронбаха
α{\displaystyle \alpha } Кронбаха определяется как
NN−1(σX2−∑i=1NσYi2σX2){\displaystyle {{{N} \over {N-1}}\left({{\sigma _{X}^{2}-\sum _{i=1}^{N}{\sigma _{Y_{i}}^{2}}} \over {\sigma _{X}^{2}}}\right)}},
где N{\displaystyle N} — число элементов в шкале, σX2{\displaystyle \sigma _{X}^{2}} — дисперсия общего тестового балла, и σYi2{\displaystyle \sigma _{Y_{i}}^{2}} — дисперсия элемента i{\displaystyle i}.
Альтернативный способ вычисления выглядит следующим способом:
α=N⋅c¯(v¯+(N−1)⋅c¯){\displaystyle \alpha ={N\cdot {\bar {c}} \over ({\bar {v}}+(N-1)\cdot {\bar {c}})}}
где N — число элементов в шкале,v¯{\displaystyle {\bar {v}}} — средняя дисперсия для выборки,c¯{\displaystyle {\bar {c}}} — среднее значение для всех ковариаций между компонентами выборки.
В настоящее время Кронбаха считают при помощи SPSS, STATISTICA и других современных статистических пакетов, возможно и при помощи Microsoft Excel
Значение α{\displaystyle \alpha } Кронбаха
Альфа Кронбаха в целом будет возрастать по мере увеличения взаимных корреляций переменных, и, поэтому, считается маркёром внутренней согласованности оценки достоверности результатов тестов. Так как максимальное взаимные корреляции между переменными по всем пунктам присутствуют, если измеряется одно и то же, альфа Кронбаха косвенно указывает на степень того, насколько все пункты измеряют одно и то же. Таким образом, альфа наиболее целесообразно использовать, когда все пункты направлены на измерение одного и того же явления, свойства, феномена. Однако, следует заметить, что высокое значение коэффициента указывает на наличие общего основания у набора вопросов, но не говорит о том, что за ними стоит один-единственный фактор — одномерность шкалы следует подтверждать дополнительными методами
Когда измеряют гетерогенную структуру, альфа Кронбаха часто будет низким. Таким образом, альфа не подходит для оценки надежности умышленно гетерогенной инструментов (например, для оригинала MMPI, в данном случае имеет смысл проводить отдельные измерения для каждой шкалы).
Считается, что профессионально разработанные тесты должны иметь внутреннюю согласованность на уровне не менее 0.70.
Коэффициент альфа может применяться и для решения другого типа задач. Так, с его помощью можно измерять степень согласованности экспертов, оценивающих тот или иной объект, стабильность данных при многократных измерениях и т.д
Теоретическое основание α{\displaystyle \alpha } Кронбаха
Метод вычисления критерия альфа Кронбаха может быть рассмотрен как расширение Кьюдера-Ричардсона-20, который является эквивалентом для работы с дихотомиями или переменными, принимающих только два значения (например, ответы истинно/ложно).
Критерий альфа Кронбаха теоретически связан с формулой прогнозирования Спирмана-Брауна. И обе эти формулы вытекают из классической теорией теста (недоступная ссылка), заключающийся в том, что достоверность результатов тестирования может быть выражена как отношение дисперсий истинной и общей оценок (ошибки и истинной оценки).
См. также
- Помимо надежности тестов, есть также надежность наблюдения — межнаблюдательская надежность. МН — это процент совпадения результатов наблюдения экспертов друг с другом.
- Анализ надёжности
- Item Response Theory
Надежность и валидность
Надежность показывает, что результаты проводимого исследования близки к истине, а валидность показывает, что результаты действительно относятся к тому явлению, которое изучается исследователем. Валидное исследование автоматически является надежным, однако обратное следствие не обязательно. Надежное исследование может и не быть валидным.
Литература
Пол Клайн. «Справочное руководство по конструированию тестов», Киев, 1994.
Ссылки
Тесты способностей. Часть 3. Надежность и валидность
Надежность и валидность — ключевые характеристики психометрического теста
Надежность показывает, что результаты проводимого исследования близки к истине.
Валидность – признак того, что результаты действительно относятся к тому явлению, которое изучается исследователем.
1. НАДЕЖНОСТЬ
НАДЕЖНОСТЬ КАК УСТОЙЧИВОСТЬ
Относительное постоянство, устойчивость, согласованность результатов теста. Независимость методики от действия случайных факторов
Устойчивость определяется с помощью повторного тестирования (ретеста)
1.1. Метод повторного тестирования (ретеста)
Ретестовая надежность определяется путем повторного обследования одних и тех же лиц при помощи одной и той же методики. Основан на подсчете корреляции индивидуальных баллов испытуемых, полученных в результате двукратного выполнения ими одного и того же теста. Чем выше коэффициент корреляции, тем выше надежность, и мы получаем примерно то же самое распределение. Обычно повторное тестирование проводится через 1-2 недели. Наименьшим удовлетворительным значением для ретестовой надежности является 0.76
Однако надежность не всех тестов можно проверять этим методом, так как оцениваемое качество, явление или эффект могут быть сами по себе нестабильны (например, наше настроение, которое может меняться от одного замера к следующему). Ещё один недостаток повторного тестирования — это эффект привыкания. Испытуемые уже знакомы с этим тестом, а может быть, даже помнят большую часть своих ответов после предыдущего заполнения.
1.2. Метод параллельных форм
Проверяется с помощью взаимозаменяемых форм теста (т.е. одни и те же обследуемые сначала обследуются с помощью одного теста, затем (через определенный интервал) с помощью другого теста). Метод эффективен, когда изначально разрабатываются параллельные варианты теста с целью ротации. Имеются трудности в доказательстве того, что обе формы — параллельные наборы заданий — являются действительно эквивалентными. Несмотря на это, на практике параллельные формы тестов оказываются полезными в установлении надежности тестов.
НАДЕЖНОСТЬ КАК СОГЛАСОВАННОСТЬ
Внутренняя согласованность (англ. — internal consistency) определяется связью каждого конкретного элемента теста с общим результатом, тем, насколько каждый элемент входит в противоречие с остальными, насколько каждый отдельный вопрос измеряет признак, на который направлен весь тест. Чаще всего тесты разрабатываются таким образом, чтобы у них была высокая степень внутренней согласованности, а связи с тем, что если одна переменная измеряется частью теста, то тогда в других частях, если они не согласованы с первой, эта же переменная измеряться не может. Таким образом, чтобы тест был валидным, необходимо, чтобы он был согласован.
Для проверки внутренней согласованности применяются различные методы:
1.3. Метод расщепления или метод автономных частей
Характеристика надежности осуществляется путем анализа устойчивости результатов отдельных совокупностей тестовых задач или единичных заданий теста. Для этого тест расщепляется/ разделяется на две равные части (например, четные и нечетные вопросы, первая и вторая половина), а затем находится корреляция между ними. Если корреляция высокая, тест можно считать надежным. Другие названия — одномоментная надежность, надежность-согласованность.
1.4. Метод эквивалентных бланков
Состоит в применении двух сопоставимых друг с другом форм теста для большой выборки. Результаты, полученные при выполнении двух форм, сравнивают и высчитывают корреляцию. Если коэффициент корреляции высокий, следовательно, тест надежен.
1.5. Метод альфа Кронбаха
В этом методе, предложенном Ли Кронбахом, сравнивается разброс каждого элемента с общим разбросом всей шкалы. Если разброс результатов теста меньше, чем разброс результатов для каждого отдельного вопроса, то каждый отдельный вопрос направлен на исследование одного и того же общего основания.
Если все вопросы измеряют один и тот же признак, то тест надежен и коэффициент альфа Кронбаха будет равен 1. При случайном разбросе результатов ответов на вопросы, коэффициент альфа Кронбаха будет равен 0, и тест ненадежен.
2. ВАЛИДНОСТЬ ТЕСТА
Валидность теста (от англ. valid – актуальный, подходящий, действительный) – понятие, указывающее, что именно тест измеряет и насколько хорошо он это делает. Это комплексная характеристика, включающая, с одной стороны, сведения о том, пригодна ли методика для измерения того, для чего она была создана, а с другой стороны, какова ее действенность, эффективность.
Не существует какого-то единого универсального подхода к определению валидности. В зависимости от того, какую сторону валидности хочет рассмотреть исследователь, используются и разные способы доказательства. Проверка валидности методики называется валидизацией.

2.1. Концептуальная валидность
Понимается как обоснование с позиции соответствия авторским представлениям об особенностях диагностируемых свойств, как мера соответствия заданий теста авторской концепции этих свойств.
2.2. Содержательная (логическая) валидность
Под содержанием понимается фактический материал, входящий в пункты тестов. Валидность по содержанию оценивает соответствие содержания теста (заданий, вопросов) той реальной деятельности, в которой проявляется измеряемое в методике свойство.
Например, чтобы тест математических способностей имел достаточный уровень содержательной валидности, его пункты не должны иметь таких формулировок, при которых для испытуемого решающими оказываются вербальные способности, необходимые для того, чтобы понять, о чём спрашивается в этом пункте.
Содержание должно быть уравновешено таким образом, чтобы все тестируемые аспекты были представлены. Тест не должен быть перегружен, допустим, пунктами на умножение в ущерб пунктам на сложение.
Установление содержательной валидности есть в значительной степени субъективная операция, основанная на мнениях «экспертов» относительно уместности используемых материалов.
2.3. Конструктная валидность (концептуальная, понятийная, внутренняя валидность)
Под конструктом понимают психологический феномен, который невозможно наблюдать непосредственно, но можно вывести из поведения человека, например, экстраверсия, общий интеллект, открытость, умения и т.д.
Конструктная валидность определяет наличие взаимосвязи между новым и ранее существующим тестом-эталоном, изучающим тот же конструкт, валидность которого была ранее определена. Она указывает на то, что разрабатываемый тест измеряет примерно ту же сферу поведения, способность, личностное качество, что и эталонная методика
При анализе конструктной валидности методики формулируют ряд гипотез о том, как будет коррелировать разрабатываемый тест с широким кругом других тестов, направленных на конструкты, находящиеся в теоретически известной или предполагаемой связи с исследуемыми. Конструктная валидность характеризуется не только связями проверяемого теста с близкородственными показателями эталонного теста, но и с теми, где, исходя из гипотезы, значимых связей наблюдаться не должно.
2.4. Операциональная валидность
Определяет степень соответствия используемой экспериментальной методики (экспериментальных утверждений) теоретическим положениям, которые положены в основу организации и проведения данного эксперимента
2.5. Очевидная (доверительная) валидность
Очевидная валидность показывает в какой степени содержание теста и его заданий (пунктов) выглядит в глазах тестируемого подходящим для данной ситуации. Именно она в первую очередь определяет отношение испытуемых к обследованию. Тест должен восприниматься испытуемым как серьезный инструмент познания его личности.
Наличие очевидной валидности способствует воспринимаемой целесообразности психологического теста и создает у тестируемого впечатления, что тест учитывает его индивидуальность и опыт работы. Позволяет добиться сотрудничества и хорошего раппорта между тестирующим и тестируемыми.
Недостаток очевидной валидности (независимо от технической валидности, или точности, теста) может вызывать у тестируемых чувства раздражения, неудовлетворенности и обманутости, создавать негативное общественное мнение.
Хотя очевидная валидность, на первый взгляд, кажется подобной содержательной валидности, смысл этих показателей различен.
2.6. Критериальная (прагматическая, эмпирическая) валидность
Такая валидность показывает ее практическую полезность. Для этого используется независимый внешний относительно самого теста критерий – показатель проявления изучаемого свойства в повседневной жизни.
Критериальная (прагматическая, эмпирическая) валидность позволяет выяснить насколько высокие или низкие результаты теста соответствуют высокой или низкой оценке того поведенческого проявления — критерия, которое он должен предсказать
Например, практическая задача теста – выявить тех, кто будет эффективен в будущей работе. Критерий «эффективность» определен как % выполнения плана продаж. В таком случае, валидный тест позволяет с определенной вероятностью отделить «выполняющих план» от «не выполняющих план».
Важно можно ли с помощью теста разделить испытуемых на эти две группы. Обладает ли тест дискриминативностью. Важно, что тест или отдельное его задание успешно (с высокими баллами) проходят «эффективные», а неуспешно (с низкими баллами) «неэффективные». В случае, когда группы отличаются друг от друга только по одной переменной, причина дифференциации бывает понятна. Но это не важно. Важно, чтобы тест умел хорошо разделять группы по целевому критерию.
Для вычисления коэффициента валидности сопоставляются результаты, полученные при применении диагностической методики, с данными, полученными по внешнему критерию, тех же лиц. Используются разные виды линейной корреляции (по Спирмену, по Пирсону).
Виды критериальной валидности:
- «Прогностическая» (предсказательная) валидность показывает возможность экстраполирования результатов на будущее. Определяется также по достаточно надежному внешнему критерию, но информация по нему собирается некоторое время спустя после испытания. Внешним критерием обычно бывает выраженная в каких-нибудь оценках способность человека к тому виду деятельности, для которой он отбирался по результатам диагностических испытаний.
- «Ретроспективная» валидность определяется на основе критерия, отражающего события или состояние качества в прошлом. Может быть использована для быстрого получения сведений о предсказательных возможностях методики.
Надёжность психологического теста — Психологос

Надёжностью называется один из критериев качества теста, его устойчивость по отношению к погрешностям измерения. Различают два вида надёжности — надёжность как устойчивость и надёжность как внутреннюю согласованность.
Надёжность как устойчивость
Устойчивость результатов теста – возможность получения одинаковых результатов у испытуемых в различных случаях.
Устойчивость определяется с помощью повторного тестирования (ретеста):
В данном методе предлагается провести несколько замеров с некоторым промежутком времени (от недели до года) одним и тем же тестом. Если корреляция между результатами различных замеров будет высокой, следовательно, тест достаточно надежный. Однако надежность не всех тестов можно проверять этим методом, так как оцениваемое качество, явление или эффект могут быть сами по себе нестабильны (например, наше настроение, которое может меняться от одного замера к следующему). Еще один недостаток МР – это эффект привыкания. Испытуемые уже знакомы с этим тестом, а может быть, даже помнят большую часть своих ответов после предыдущего заполнения.
Надёжность как внутренняя согласованность
Внутренняя согласованность определяется связью каждого конкретного элемента теста с общим результатом, тем, насколько каждый элемент входит в противоречие с остальными, насколько каждый отдельный вопрос измеряет признак, на который направлен весь тест.
Для проверки внутренней согласованности применяются:
- Метод расщепления или метод автономных частей
- Метод эквивалентных бланков
- Альфа Кронбаха
Метод расщепления (Split-half reliability)
Этот метод заключается в расщеплении/разделении теста на две равные части (например, четные и нечетные вопросы, первая и вторая половина), а затем находится корреляция между ними. Если корреляция высокая, тест можно считать надежным.
Метод эквивалентных бланков
МЭБ состоит в применении двух сопоставимых друг с другом форм теста для большой выборки (например, формы L и M для измерения в шкале интеллекта Стэнфорда-Бине)
Результаты, полученные при выполнении двух форм, сравнивают и высчитывают корреляцию. Если коэффициент корреляции высокий, следовательно, тест надежен. Недостаток этого метода в том, что он подразумевает такой длительный и трудоемкий процесс, как создание двух эквивалентных форм.
Альфа Кронбаха
В этом методе, предложенном Ли Кронбахом, сравнивается разброс каждого элемента с общим разбросом всей шкалы. Если разброс результатов теста меньше, чем разброс результатов для каждого отдельного вопроса, следовательно, каждый отдельный вопрос направлен на исследование одного и того же признака, свойства или явления. Они вырабатывают значение, которое можно считать истинным. Если такое значение выработать нельзя, то есть получается случайный разброс при ответе на вопросы, тест не надежен и коэффициент альфа Кронбаха будет равен 0. Если же все вопросы измеряют один и тот же признак, то тест надежен и коэффициент альфа Кронбаха в этом случае будет равен 1.
Помимо надежности тестов, есть также надежность наблюдения – межнаблюдательская надежность. МН – это процент совпадения результатов наблюдения экспертов друг с другом.
Надежность и валидность
Надежность показывает, что результаты проводимого исследования близки к истине, а валидность показывает, что результаты действительно относятся к тому явлению, которое изучается исследователем. Валидное исследование автоматически является надежным, однако обратное следствие не обязательно. Надежное исследование может и не быть валидным.


Что такое, методы, инструменты, пример
![]()
- На главную
Тестирование
- Назад
- Agile-тестирование
- BugZilla
- Cucumber
- Тестирование базы данных
- 9000 J5000 J5000 Тестирование базы данных
- Назад
- JUnit
- LoadRunner
- Ручное тестирование
- Мобильное тестирование
- Mantis
- Почтальон
- QTP
- Назад
- 00050005000500050005000 RPM
000
000 RPM
- Управление тестированием
- TestLink
SoapUI
SAP
- Назад
- ABAP 9 0005
- APO
- Начинающий
- Basis
- BODS
- BI
- BPC
- CO
- Назад
- CRM
- Crystal Reports
- QMO
000
- Заработная плата
000 HRM
- Назад
- PI / PO
- PP
- SD
- SAPUI5
- Безопасность
- Менеджер решений
- Successfactors
- Учебники SAP
Apache
- Назад
- Java
- JSP
- Kotlin
- Linux
- Linux
- Kotlin
- Linux
- Perl
js
- Назад
- PHP
- PL / SQL
- PostgreSQL
- Python
- ReactJS
- Ruby & Rails
- Scala
- SQL
- UML
- VB.Net
- VBScript
- Веб-службы
- WPF
000
0004 SQL
Обязательно учите!
- Назад
- Бухгалтерский учет
- Алгоритмы
- Android
- Блокчейн
- Business Analyst
- Веб-сайт сборки
- CCNA
- Облачные вычисления
- COBOL 9000 Compiler
- 0005
- Ethical Hacking
- Учебные пособия по Excel
- Программирование на Go
- IoT
- ITIL
- Jenkins
- MIS
- Сетевые подключения
- Операционная система
- Назад
- 9000 Встроенный COBOL 9000 Дизайн 9000
Управление проектами Обзоры
- Salesforce
- SEO
- Разработка программного обеспечения
- VB A
- 0005
Big Data
- Назад
- AWS
- BigData
- Cassandra
- Cognos
- Хранилище данных
0005
HBOps
HBOps
.
Что такое тестирование надежности: определение, метод и инструменты
Что такое тестирование надежности?
Надежность определяется как вероятность безотказной работы программного обеспечения в течение определенного периода времени в конкретной среде.
Тестирование надежности выполняется, чтобы убедиться, что программное обеспечение надежно, соответствует цели, для которой оно создано, в течение определенного периода времени в данной среде и способно обеспечить безотказную работу.
В этом механизированном мире сегодня люди слепо верят в любое программное обеспечение. Какой бы результат ни показывала программная система, люди следят за ней, веря, что программа всегда будет правильной. На самом деле это распространенная ошибка, которую все мы совершаем.
Пользователи считают, что показанные данные верны, и программное обеспечение всегда будет работать правильно. Здесь возникает необходимость в тестировании надежности.

Согласно ANSI надежность программного обеспечения определяется как вероятность безотказной работы программного обеспечения в течение определенного периода времени в конкретной среде.
Если программный продукт работает без сбоев в течение определенного периода времени в определенной среде, то он известен как надежное программное обеспечение.
Надежность программного обеспечения снизит количество отказов при разработке программного обеспечения. В электронных устройствах или механических инструментах программное обеспечение не может иметь «износ», здесь «износ» происходит только из-за «дефектов» или «ошибок» в программной системе.
Рекомендуем прочитать => Советы и приемы по поиску ошибки
Что такое тестирование надежности?
В современном мире программные приложения используются во всех без исключения аспектах нашей жизни, включая здравоохранение, государственный сектор, телекоммуникации и т. Д.
Следовательно, нам нужны точные данные, на которые пользователи могут положиться. Тестирование надежности связано с качеством программного обеспечения и стандартизацией продуктов. Если мы можем повторить тестовые примеры и постоянно получать один и тот же результат, то продукт считается «надежным».
Тестирование надежности выполняется, чтобы убедиться, что программное обеспечение надежно, соответствует цели, для которой оно создано, в течение определенного периода времени в данной среде и способно обеспечить безотказную работу.
Когда мы используем тестирование надежности?
Ниже приведены сценарии, в которых мы используем это тестирование:
- Чтобы найти неисправности, присутствующие в системе, и их причину.
- Для обеспечения качества системы.
Тестовые примеры должны быть разработаны таким образом, чтобы обеспечить полное покрытие программного обеспечения. Тестовые примеры должны выполняться через равные промежутки времени, чтобы мы могли перекрестно проверить текущий результат и предыдущий результат и проверить, есть ли между ними какая-либо разница.Если он показывает такой же или похожий результат, то программное обеспечение можно считать надежным.
Кроме того, мы можем проверить надежность, выполнив тестовые примеры в течение определенного периода времени и проверив, правильно ли он показывает результат без каких-либо сбоев по истечении этого определенного периода времени. Выполняя тестирование надежности, мы должны проверить ограничения среды, такие как утечка памяти, низкий заряд батареи, низкий уровень сети, ошибки базы данных и т. Д.
Основные типы для измерения надежности программного обеспечения
Ниже перечислены несколько основных типов для оценки надежности программного обеспечения.
1) Тестирование-повторное тестирование надежности
Рассмотрим следующую ситуацию, в которой мы тестируем функциональность, скажем, в 9:30 утра и снова тестируем ту же функциональность в 13:00. Позже мы сравним оба результата. Мы получаем высокую корреляцию результатов. Тогда мы можем сказать, что тест «Надежный». Обычно надежность 0,8 или более означает, что систему можно рассматривать как высоконадежный продукт.
Здесь очень важно отметить, что длина теста остается прежней, если у нас есть 10 шагов в тестовом примере, то количество шагов останется таким же для выполнения теста в следующий раз.

Рассмотрим конкретный пример человека, проходящего «тест IQ» и набравшего 144 балла. Через 6 месяцев он сдает тот же «тест на IQ» и набирает 68 баллов. В таком случае он не может считаться «надежным» источником.
2) Параллельная или альтернативная форма надежности
Это называется так, поскольку тестировщики проводят тестирование в двух формах одновременно.

3) Надежность между оценщиками
Надежность между оценщиками также известна как надежность между наблюдателями или кодировщиками.Это особый тип надежности, состоящий из нескольких оценщиков или судей. Он касается согласованности рейтинга, выставляемого разными оценщиками / наблюдателями.

Например, , рассмотрим участника, участвующего в певческом конкурсе и получившего 9,8,9 (из 10) баллов от нескольких судей. Этот балл можно считать «надежным», поскольку он достаточно согласован. Но если он набрал 9,3,7 (из 10), то это нельзя считать «надежным».
Примечание: Эти рейтинги будут сильно зависеть от общего согласия между различными судьями / рейтерами. После того, как вы проведете серию наблюдений, вы можете решить, что существует определенная стабильность в оценках, и по прошествии этого периода времени мы можем сказать, что они стабильны.
Таким образом, стабильность подсчета очков измеряется несколькими наблюдателями. Очень важно отметить, что навыки наблюдателя также играют важную роль при обсуждении межэкспертной надежности.Для повышения надежности между оценщиками оценщики нуждаются в обучении или надлежащем руководстве.

Рассмотрите таблицу Excel выше и просмотрите оценки, выставленные двумя разными оценщиками Rater1 и Rater2 для 12 различных пунктов. Rater1 независимо выставил оценку на доске для подсчета очков. Здесь, используя табло, мы собираемся вычислить процент согласия между двумя оценщиками. Это называется надежностью между экспертами или соглашением между двумя экспертами.
В третьем столбце мы поставим «1», если оценки, выставленные рейтерами, совпадают. Мы дадим «0», если оценки совпадают. После этого мы найдем в столбце цифры «1» и «0». Здесь 8.
Количество «1» = 8
Общее количество элементов = 12
Процент согласия = (8/12) * 100 = 67%. 67% — это не так уж и много. Оценщикам необходимо больше согласия, чтобы они могли обсудить и соответствующим образом улучшить результат.
Различные типы тестирования надежности
Различные типы тестирования надежности обсуждаются ниже для справки:
1) Тестирование характеристик:
Это тестирование определяет пригодность, т.е.е. он проверяет, работает ли приложение должным образом при использовании с отступом. Здесь он проверит совместимость приложения для тестирования его с другими компонентами и системой, которая взаимодействует с приложением.
Он обеспечивает точность системы, чтобы проверить, нет ли ошибок, обнаруженных во время бета-тестирования.
Кроме того, он проверяет некоторую безопасность и соответствие. Тестирование безопасности связано с предотвращением несанкционированного доступа к приложению, намеренного или непреднамеренного.В соответствии с требованиями мы проверим, соответствует ли приложение определенным критериям, таким как стандарт, правила и т. Д.
2) Нагрузочное тестирование
Нагрузочное тестирование проверит, насколько хорошо система работает по сравнению с конкурирующей системой или производительностью. Он также основан на количестве одновременных пользователей, использующих систему, и поведении системы по отношению к пользователям.
Система должна отвечать на команды пользователя с меньшим временем отклика (скажем, 5 секунд) и соответствовать ожиданиям пользователя.
3) Регрессионное тестирование
В рамках регрессионного тестирования мы проверим, хорошо ли работает система и не было ли ошибок в результате добавления новых функций в программное обеспечение. Это также делается, когда ошибка была исправлена и тестировщику необходимо снова ее протестировать.
План тестирования надежности
На разных этапах SDLC (жизненного цикла разработки программного обеспечения) пользователи могут задавать много вопросов о будущем продукта, например, «надежны они или нет».Нам нужно иметь четкое решение для таких вопросов. Имея правильную модель, мы можем предсказать продукт.
К двум типам моделей относятся:
- Модель прогнозирования
- Модель оценки
При прогнозном тестировании мы прогнозируем результат с помощью исторических данных, статистики, машинного обучения и обучения. Все, что нам нужно, это написать отчет. В прогнозной модели мы получаем только некоторую историческую информацию. Используя эту информацию, мы можем построить диаграмму рассеяния и провести экстраполированную линию к существующим историческим данным, а также предсказать будущие данные.
Этот тип модели выполняется перед самой стадией разработки или тестирования. В оценочном тестировании, помимо использования исторических данных, мы будем использовать текущие данные. Здесь мы можем спрогнозировать надежность продукта в настоящем или будущем. Этот тип тестирования выполняется на последних этапах жизненного цикла разработки программного обеспечения.
Инструменты для тестирования надежности
Тестировщикам необходимо выполнить оценку надежности программного обеспечения. Это приведет к использованию различных инструментов для обеспечения надежности программного обеспечения.
Используя стандартизированный инструмент, мы можем:
- Обнаружить информацию об отказе.
- Выберите правильную модель, чтобы сделать прогноз относительно программного обеспечения.
- Создавать отчеты о сбоях.
На рынке доступны различные инструменты для измерения надежности программного обеспечения, некоторые из них упомянуты ниже:
CASRE (Компьютерный инструмент оценки надежности программного обеспечения): Это не бесплатная программа, нам необходимо приобрести Это.
Инструмент измерения надежности CASRE построен на основе существующих моделей надежности, которые помогают лучше оценивать надежность программного продукта. Графический интерфейс инструмента позволяет лучше понять надежность программного обеспечения, а также очень прост в использовании.
Во время теста это помогает пользователям узнать, увеличивается или уменьшается надежность системы при использовании набора данных об отказах. Carse предоставляет двухмерный вид, отображая количество отказов в зависимости от времени интервала тестирования, и, таким образом, пользователь может получить график, представляющий систему, как показано на рисунке ниже.

Использование CASRE
- Пользователь может выбрать данные об ошибках.
- Указывая, насколько далеко в будущем мы хотим спрогнозировать надежность продукта.
- Выберите модели надежности.
- Выберите подходящую модель по результату.
- Распечатать результат ошибки.
- Сохраните результат на диск.
Другие инструменты, используемые для тестирования надежности, включают SOFTREL, SoRel (анализ и прогнозирование надежности программного обеспечения), WEIBULL ++ и т. Д.
Заключение
Тестирование надежности стоит дорого по сравнению с другими формами тестирования. Следовательно, чтобы сделать это рентабельно, нам необходимо иметь надлежащий план тестирования и управление тестированием.
В SDLC важную роль играет проверка надежности. Как объяснялось выше, использование показателей надежности повысит надежность программного обеспечения и спрогнозирует будущее программного обеспечения. Часто бывает трудно добиться надежности программного обеспечения, если оно имеет высокую сложность.
.
Проверка надежности — Психометрические тесты
Что это такое?
Надежность теста — это определение того, насколько согласована мера конкретного элемента в течение определенного периода времени и между разными участниками. Например, тест, измеряющий личностные черты, должен давать одни и те же ответы для испытуемого после многократного прохождения теста и с коротким промежутком времени между ними (при условии, что индивидуум не изменил по своей сути черты личности).
У надежности есть подтипы, которые должны быть удовлетворены, прежде чем тест или оценка будут признаны таковыми.
Надежность параллельных форм — Измеряется, когда есть два разных теста, использующих один и тот же контент, но с разным оборудованием или процедурами; если результаты, полученные в результате оценок, остаются прежними, то надежность параллельных форм удовлетворена.
Надежность внутренней согласованности — Проверяет элементы в тесте, чтобы оценить внутреннюю надежность между элементами.Например, в личностном тесте может показаться, что два или более вопроса задают одно и то же. Если участник отвечает на них одинаково, то внутренняя надежность считается правильной.
Надежность между оценщиками — Используется два человека для оценки или оценки результатов психометрического теста, если их баллы или рейтинги сопоставимы, то надежность между экспертами подтверждается.
Надежность повторного тестирования — Это последний подтип, который достигается путем проведения одного и того же теста в два разных времени и получения одинаковых результатов каждый раз.
Прочие факторы
Всегда будут небольшие расхождения в общей надежности теста, так как практически невозможно найти все дефекты; Кроме того, люди, проходящие тест, могут свободно отвечать, и день ото дня могут иметь разные мысли или чувства. На это можно взглянуть двояко: факторы, способствующие согласованности, и факторы, способствующие непоследовательности. Последовательность объясняется стабильными чертами или характеристиками индивидуума, проходящего тест, например ростом и весом.Непоследовательность объясняется множеством разных факторов, например, состоянием здоровья участника в день тестирования, его пониманием теста или удачей в выборе случайно правильного ответа.
Почему важна надежность?
Надежность теста важна, особенно при работе с психометрическими тестами; Нет смысла проводить тест, который будет давать разные ответы каждый раз, особенно когда он может повлиять на решения работодателей и на то, кого они могут нанять для руководства своей компанией.
.
Что такое надежность повторного тестирования и почему это важно?
Что такое надежность повторного тестирования?
Когда вы приходите к выбору инструментов измерения для своего эксперимента, важно убедиться, что они действительны (т. Е. Правильно измерить рассматриваемую конструкцию или домен), и что они также могут надежно воспроизвести результат более одного раза в одной и той же ситуации. и население.
В эксперименте с несколькими временными точками можно надеяться, что выбранный инструмент измерения сможет постоянно воспроизводить один и тот же результат во всех посещениях, при условии, что все остальные переменные остаются неизменными. Инструменты, которые действительно обеспечивают такую согласованность, считаются имеющими высокую надежность повторных тестов и, следовательно, подходящими для использования в продольных исследованиях.
Прочтите наши статьи
Почему важно выбирать меры с хорошей надежностью?
![]() Наличие хорошей надежности повторного тестирования означает внутреннюю валидность теста и гарантирует, что измерения, полученные за один сеанс, будут репрезентативными и стабильными во времени.Часто анализ надежности повторного тестирования проводится в двух временных точках (T1, T2) в течение относительно короткого периода времени, чтобы не допустить выводов, сделанных из-за возрастных изменений в производительности, а не из-за плохой стабильности теста.
Наличие хорошей надежности повторного тестирования означает внутреннюю валидность теста и гарантирует, что измерения, полученные за один сеанс, будут репрезентативными и стабильными во времени.Часто анализ надежности повторного тестирования проводится в двух временных точках (T1, T2) в течение относительно короткого периода времени, чтобы не допустить выводов, сделанных из-за возрастных изменений в производительности, а не из-за плохой стабильности теста.
Без хорошей надежности вам трудно поверить в то, что данные, предоставленные с помощью меры, являются точным представлением о работе участника, а не связаны с нерелевантными артефактами в сеансе тестирования, такими как экологические, психологические или методологические процессы.
Часто вашей целью в исследовании будет оценка влияния вмешательства на работу человека. Без уверенности в надежности выбранной вами меры трудно установить, действительно ли различия в показателях до и после вмешательства связаны с предоставленным вмешательством, а не с артефактом инструмента.
Таким образом, инструмент с низкой надежностью может замаскировать истинные эффекты вмешательства, которые могут иметь серьезные последствия для сделанных выводов и, следовательно, будущего развития этого вмешательства.
Как рассчитывается надежность повторного тестирования?
Традиционно подход к оценке надежности оценок заключался в установлении степени взаимосвязи между статистикой теста. Таким образом, если инструмент измерения постоянно дает один и тот же результат, связь между этими точками данных будет высокой.
Чтобы ответить на вопрос о взаимосвязи, исследователи часто обращались к вычислению коэффициента корреляции (r), который измеряет силу взаимосвязи.Таким образом, измерительный инструмент, обеспечивающий одинаковые выходные данные в каждый момент времени, обеспечил бы идеальную линейную корреляцию r = 1.
Однако, несмотря на то, что полезно знать степень взаимосвязи между точками данных, истинный вопрос, который мы стремимся выяснить с помощью проверки надежности повторного тестирования, — это степень соответствия между точками времени, а не взаимосвязь.
Когда мы используем одну и ту же меру в одной и той же популяции для T1 и T2, очень возможно получить высокую степень взаимосвязи, измеренную с помощью коэффициента корреляции, но при этом показать плохой уровень согласия (Bland & Altman, 1986).
На вопрос об установлении согласованности между точками данных, а не взаимосвязи, можно ответить с помощью статистической процедуры Бланда и Альтмана (1986), которая может резюмировать отсутствие согласия путем вычисления смещения.
Построив точки данных и вычислив разницу между каждой точкой данных и средним значением (средняя разница) вместе со стандартным отклонением, мы можем оценить, насколько приемлемы меры. Мы ожидаем, что 95% различий будут менее чем на два стандартных отклонения от среднего, что позволит нам определить, насколько приемлемы меры на основе того, насколько близко точки данных отклоняются от линии равенства.
Узнайте больше о нашей науке
Надежность повторного испытания CANTAB:
В литературе существует множество работ, в которых рассчитывается надежность наших тестов CANTAB при повторном тестировании, при этом общий вывод демонстрирует относительно хорошую надежность (Lowe & Rabbitt, 1998).
Однако выводы, сделанные на основе анализа литературы, в значительной степени зависят от критериев исхода, выбранных исследователями для исследования, и часто связаны с исследовательским вопросом этих людей.
Следовательно, нецелесообразно резюмировать заключение о надежности повторного тестирования для общей задачи CANTAB на основе анализа одного показателя результата, а вместо этого следует оценивать несколько показателей результата, особенно применимых к большинству исследовательских проектов.
В настоящее время мы проводим обновленный анализ учетных данных надежности повторного тестирования наших задач с использованием этих более подходящих статистических показателей по критериям результатов, которые чаще всего рекомендуются для экспериментов.
Некоторые из наших предварительных анализов поступают, и мы рады поделиться этими результатами в ближайшем будущем.
В качестве тизера взгляните на наш последний анализ задачи обучения парных партнеров (PAL). Приведенные ниже данные получены с использованием показателя результатов PAL с поправкой на общие ошибки (PALTEA) при сравнении двух отдельных посещений одних и тех же участников (N = 45).

График Бланда-Альтмана, приведенный выше, представляет собой особый вариант диаграммы рассеяния. Ось x представляет базовое значение, которое равно среднему значению оценок T1 и T2 для каждого участника; ось Y отображает разницу между двумя оценками.Сплошная горизонтальная линия представляет собой общее среднее значение, а пунктирная линия означает «нулевую разницу»: в чисто идеальном случае идеального согласия между двумя методами или, как в нашем случае, двух идентичных оценок T1 и T2, все точки будет лежать на пунктирной линии. Верхняя пунктирная линия показывает 2 стандартных отклонения от среднего, а нижняя пунктирная линия представляет -2 стандартных отклонения. Основываясь на клинических и экспериментальных соображениях и целях, ученый (и) должен определить априори приемлемые пределы для графика Бланда-Альтмана.Наконец, гистограммы на осях графиков показывают нам распределение частоты оценок: например, чем выше столбец, тем больше количество точек с заданным значением в нашем наборе данных.
Приведенные выше данные представляют собой краткий снимок анализа, который в настоящее время проводится, чтобы еще раз подтвердить надежность наших задач CANTAB на нашей новейшей платформе CANTAB Connect. Мы опираемся на опубликованную литературу, которая уже демонстрирует хорошую надежность повторных тестов для CANTAB, и предоставляем более полный объем работы для всех наших задач по более широкому спектру показателей результатов.Мы будем держать вас в курсе о ходе реализации этого проекта и с нетерпением ждем возможности предоставить больше данных о надежности, когда мы скоро закончим расчет цифр.
Свяжитесь с нами
Список литературы
Бланд, М., Дж., И Альтман, Д. (1986). Статистические методы оценки соответствия между двумя методами клинических измерений. Ланцет, 327 (8476), 307–310. DOI: 10.1016 / s0140-6736 (86) 90837-8
Джаварина Д. (2015). Понимание анализа Блэнда Альтмана.Biochemia Medica, 25 (2), 141–151. http://doi.org/10.11613/BM.2015.015
Lowe, C., & Rabbitt, P. (1998). Тестирование \ повторное тестирование нейропсихологических батарей CANTAB и ISPOCD: теоретические и практические вопросы. Нейропсихология, 36 (9), 915–923. DOI: 10.1016 / s0028-3932 (98) 00036-0
Теги: цифровое здоровье | кантаб | техника | нейробиология | надежность | тест-повторное тестирование
.